방송대 파이썬 프로그래밍 기초 - 12강. 파일

1. 파일의 이해
파일의 역할
파일(file) : 컴퓨터에 의해 처리될 또는 처리된 데이터와 정보가 임시적으로 저장된 상태
- 일련의 연속된 바이트
- 프로그램(파이썬 소스코드)에 읽혀 가공, 처리 후 다시 파일에 기록시킴.
파일의 구성
연속된 바이트와 파일의 시작, 파일 포인터, 파일의 끝(EoF)으로 표현

파일의 종류
데이터가 저장되는 방식에 따라 텍스트 파일과 바이너리 파일로 구분됨.
두 파일을 쉽게 구분하는 방법 : 텍스트 에디터로 열리면 텍스트 파일, 그렇지 않으면 바이너리 파일
대다수의 파일은 다 바이너리 파일임.
| 텍스트 파일 | 바이너리 파일 |
 |
 |
| 199를 '1', '9', '9'라는 서로 다른 개별 문자로 인식함. 인코딩 시스템이 아스키코드 값이라면 아스키코드의 1,에 해당되는 바이트, 9에 해당되는 바이트 두 개를 기록함. 해당 텍스트 파일에는 1, 9, 9라고 하는 문자가 적혀있다는 방식으로 해석함. |
199를 개별 문자로 인식하는 게 아니라 실제 바이너리 숫자로 저장함. 199는 0부터 255 또는 -127에서 128까지 1바이트 또는 2바이트로 기록함. (훨씬 더 적은 데이터 용량으로 실제 데이터 값을 저장 가능함.) |
| - 주로 아스키코드 또는 유니코드 인코딩을 사용함. - 일반적으로 텍스트 파일은 바이너리 파일보다 큼. |
- 특정 인코딩을 사용하지 않음. - 일반적으로 바이너리 파일은 텍스트 파일보다 용량이 적음. |
파일 함수
파일의 시작, 파일 포인터, 파일의 끝을 활용하여 데이터 읽기, 쓰기를 위한 함수 및 메소드를 내장
| 멤버 | 설명 |
| open():file obj | 파일과 연결되어 있는 파일 객체 생성 |
| read() | 특정 개수의 문자를 반환 |
| readline() | 한 라인의 문자열을 반환 |
| readlines(): list | 전체 라인의 문자열을 리스트로 반환 |
| write(s: str): | 파일에 문자열을 작성 |
| close() | 파일 닫기 및 파일 객체 삭제 close()를 하지 않았을 경우 잘못된 연산이 이루어지거나 파일이 깨질 수도 있으니 주의 |
# open(): 파일과 연결된 파일 객체 생성
file = open("example.txt", "r")
# → "example.txt" 파일을 읽기 모드("r")로 열고, 파일과 연결된 파일 객체 file을 생성
# read(): 특정 개수의 문자를 반환
data = file.read(10)
print(data)
# → 파일 객체 file에서 최대 10개의 문자를 읽고, 읽은 내용을 변수 data에 저장하고 출력
# write(s: str): 파일에 문자열을 작성
file.write("Hello, World!")
# → 파일 객체 file에 문자열 "Hello, World!"를 작성
# close(): 파일 닫기 및 파일 객체 삭제
file.close()
# → 파일 객체 file을 닫아서 파일과의 연결을 종료
# 파일을 사용한 후에는 close()를 호출하여 메모리 누수를 방지
# readline() 함수 : 한 라인의 문자열을 반환
# readlines() 함수 : 전체 라인의 문자열을 리스트로 반환파일 객체 생성
객체는 생성-사용-삭제의 과정을 거치는데, 파일 객체도 마찬가지임.
가비지 컬렉터(Garbage collector : 파이썬 인터프리터가 참조변수로 쓰이지 않는 객체들을 주기적으로 점검하고 정리하여 프로그램의 메모리 사용량을 최적화하는 기능
구문형식

→ 물리적인 파일과 연결된 파일 객체를 생성하고 참조변수에 할당
| 모드 | 설명 |
| 'r' | 읽기 용도 |
| 'w' | 새로운 파일을 쓰기 용도 |
| 'a' | 파일의 끝에 데이터를 덧붙이기 용도 |
파일 이름
파일의 고유 식별자 역할 및 저장장치 내부에서 파일의 위치를 표현하는 파일경로를 내포
해당 파일에 접근하기 위한 모든 정보가 다 들어있음.
파이썬 프로그램이 텍스트 파일과 같은 폴더에 있다면 앞의 경로 생략 가능함.

리눅스의 파일 시스템 구조로 만들기 : 드라이브 → var → etc → python.py
파일 읽기
특정 범위의 데이터를 파일에서 읽고 문자열로 반환
파이썬에서는 파일을 읽을 때 파일 포인터의 이동이 일어남.
- 파일 포인터는 현재 파일에서 읽거나 쓸 위치를 가리키는 역할을 함.
- 파일을 읽을 때마다 파일 포인터는 읽은 데이터의 끝으로 자동으로 이동됨.
file = open("example.txt", "r")
data1 = file.read(5)
print(data1) # 출력: "Hello"
# 파일 포인터는 "Hello"의 뒤에 위치한 상태
data2 = file.read(5)
print(data2) # 출력: "\nWorl"
# 파일 포인터는 "Hello\nWorl"의 뒤에 위치한 상태
data3 = file.read()
print(data3) # 출력: "d\nPython"
# 파일 포인터는 파일의 끝에 위치한 상태
file.close()
\n (new line character) : 한 줄을 밑으로 내리라는 의미
h_fp = open("Hamlet_by_Shakespeare.txt", "r")
# 경로가 없음 → 같은 폴더 내에 있음
# open() 함수 : 파일과 연결된 객체 생성
# r : 읽기 모드 사용
# 'h_fp'라고 하는 참조변수로 메소드를 부름.
title = h_fp.read(6)
# 파일 포인터가 이동하면서 최대 6개의 문자를 읽음.
# title에는 'Hamlet'이 문자열 형태로 저장됨.
# read 함수 : 입력 파라미터 만큼의 바이트 수 만큼 파일 포인터로 읽어서 데이터를 반환함.
author = h_fp.readline()
# realine 함수 : 다음에 있는 개행 포인터(\n)가 나올 때까지 쭉 읽어들임.
# author에는 'by William Shakespeare'라고 하는 문자열이 들어감.
h_fp.close()
# 파일 포인터를 닫아서 삭제함.| read() 함수 | readline() 함수 | |
| 파라미터 O | 파일에서 지정한 개수의 문자를 읽어서 반환함. | 파일에서 지정한 개수의 줄의 문자열을 읽어서 반환함. |
| 파라미터 X | 파일 전체 내용을 읽어옴. | 파일에서 한 줄의 문자열을 읽어서 반환함. (\n이 나올 때까지) |
파일 쓰기
문자열을 파일 포인터가 위치한 지점에 기록함.
"w" 모드는 파일을 새로 생성하고, 파일 포인터가 맨 앞으로 위치함.
동일한 파일 이름을 입력한 경우, 기존 파일이 이미 존재하면 해당 파일의 내용은 모두 삭제되고 새로운 파일이 생성됨.
→ 이미 존재하는 파일을 덮어쓰게 되므로 파일을 생성하기 전에 기존 파일의 내용을 백업하거나, 파일이 존재하는지 확인하는 등의 조치를 취하는 것이 좋음.

p_fp = open("python.txt", "w")
# 'python.txt'라는 파일을 쓰기모드(w)로 열기
# 이미 동일한 이름의 파일이 있다면 해당 파일의 내용은 모두 삭제됨.
# 파일과 연결된 파일 객체는 p_fp라는 변수에 할당됨.
p_fp.write("KNOU\n")
# 파일 객체인 p_fp를 통해 "KNOU"라는 문자열을 파일에 작성함.
# KNOU가 한 줄에 작성됨.
p_fp.write("python programming\n")
# p_fp를 통해 'python programming'이라는 문자열을 파일에 작성함.
p_fp.close()
# 파일을 닫고 파일과 연결된 파일 객체를 삭제함(flushing).
# 특히 쓰고 나서의 close가 더 중요함!
# 'python.txt' 파일에는 'KNOU'와 'python programmming'이라는 텍스트가 작성되어 있음.데이터 추가 (a모드, append 모드)
파일의 끝에 데이터를 덧붙이는 작업
- 파일 오픈 후 파일 포인터를 EoF(맨 뒤)로 이동
- 존재하지 않는 파일을 a모드로 실행하면 write와 동일

a_fp = open("python.txt", "a")
# "python.txt" 파일을 이어쓰기 모드("a")로 열기
# 이어쓰기 모드는 기존 파일의 끝 부분에서부터 작성을 시작함.
# 파일과 연결된 파일 객체는 a_fp라는 변수에 할당됨.
a_fp.write("\nby CS\n")
# 파일 객체인 a_fp를 통해 "\nby CS\n"이라는 문자열을 파일에 작성함.
# \n을 통해 다음 줄에 작성되도록 함.
# "by CS"가 새로운 줄에 작성됨.
a_fp.close()
# 파일을 닫고 파일과 연결된 파일 객체를 삭제함.
# 파일을 닫으면 해당 파일에 대한 작업을 모두 마치게 됨.파일 읽고 쓰고 수정하는 프로그램
'Khan.txt' 파일을 읽고 처리하는 프로그램을 작성하시오.
- 모든 내용을 출력하시오.
- 마지막에 '-칭기스 칸-'을 삽입하시오.
깃헙에서 파일 다운 받기
https://github.com/jaehwachung/Python-Programming
GitHub - jaehwachung/Python-Programming: 한국방송통신대학교 컴퓨터과학과 파이썬 프로그래밍 기초
한국방송통신대학교 컴퓨터과학과 파이썬 프로그래밍 기초. Contribute to jaehwachung/Python-Programming development by creating an account on GitHub.
github.com



Colab에서 실습하기 위해 다운로드한 파일을 Colab에 업로드하기
khan.txt의 위치 : 개인 컴퓨터 바탕화면
프로그램 코드 실행 위치 : 구글 서버 어딘가
→ Github 사이트에서 다운로드 된 파일을 우리가 여기 있는 코랩에다 올려줘야 됨.



주의할 점은 85GB의 저장공간이 있다고 해서 개인 파일을 업로드하면 안 된다는 것임.
이 창을 닫으면 구글에서 여기 있는 자원들을 삭제하고 가져가기 때문에 없어짐.
Colab에 업로드한 파일의 접근 경로 알아보기

점 3개 있는 부분 누르고 '경로 복사' 누르기
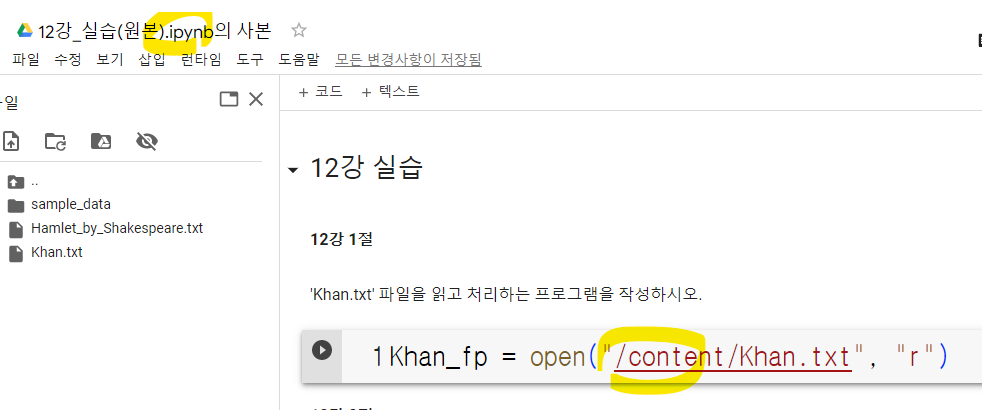
실행하고 있는 ipynb 파일은 content 폴더 밑에 있음.
텍스트 파일과 ipynb 파일이 같은 폴더에 있으므로 앞의 경로 생략 가능함.
Khan_fp = open("/content/Khan.txt", "r")
print(Khan_fp.read(10)) #1 0글자
print(Khan_fp.readline()) # 새로운 개행문자 이전까지
Khan_fp.close()
텍스트 한 줄씩 읽고 출력하기
Khan_fp = open("/content/Khan.txt", "r")
for motto in Khan_fp.readlines() :
# 한 줄 씩 리스트로 읽으라는 명령
print(motto)
Khan_fp.close()
\n으로 한 줄 띄우고, print로 한 줄 띄워지면서 문장과 문장 사이에 새로운 줄이 생겨버림.
→ 문자열에 있는 개행문자를 지우면 됨.
str메소드를 사용하여 개행문자를 지우기

Khan_fp = open("/content/Khan.txt", "r")
for motto in Khan_fp.readlines() :
# 한 줄 씩 리스트로 읽으라는 명령
print(motto.strip())
# strip() 메서드는 문자열의 양쪽 끝에 있는 공백 문자와 개행 문자를 제거함.
# 별도의 인자로 개행 문자(\n)를 전달할 필요가 없음.
Khan_fp.close()
텍스트 파일 맨 뒤에 새로운 텍스트 삽입
Khan_fp = open("Khan.txt", "a")
Khan_fp.write("\n")
Khan_fp.write(format("-칭기스 칸-", ">50s"))
Khan_fp.close()
파일을 다운로드하여 수정이 잘 되었는지 확인하기

2. 파일의 활용
시퀀스의 개념
순서화된 값의 집합체를 저장할 수 있는 데이터 타입
- 단일 식별자로 연속된 저장 공간 접근 수단 제공
- 개별 원소의 값을 수정, 추가, 삭제 가능
- 원소(element)의 나열을 저장할 수 있는 타입
→ 리스트, 세트, 투플, 딕셔너리 등 (특성에 따라 종류가 구분됨)

순서화된 번지수가 아니라 영문 단어를 방 번호 대신 사용하고, 그 방 번호에 맞는 값들을 저장할 수 있는 구조를 찾고 싶음.
딕셔너리의 이해
· 딕셔너리(dictionary) : 키와 값의 쌍(pair)을 저장하는 시퀀스
· 키(key) : 딕셔너리 내에서 고유한 식별자 역할, 값에 접근하기 위한 인덱스
· 값(value) : 키와 연결된 데이터
· 항목(item) : 딕셔너리에서 키와 값의 쌍

번지도 사용자가 마음껏 결정할 수 있는 구조
# 딕셔너리 생성
student = {
"name": "John",
"age": 20,
"grade": "A"
}
# 딕셔너리 값 접근
print(student["name"]) # 출력: John
print(student["age"]) # 출력: 20
# 딕셔너리 값 변경
student["grade"] = "B"
print(student["grade"]) # 출력: B
# 딕셔너리에 새로운 항목 추가
student["major"] = "Computer Science"
print(student) # 출력: {'name': 'John', 'age': 20, 'grade': 'B', 'major': 'Computer Science'}
# 딕셔너리에서 키와 값을 함께 순회
for key, value in student.items():
print(key, ":", value)
# 출력:
# name : John
# age : 20
# grade : B
# major : Computer Science
# 딕셔너리에서 키의 유무 확인
if "name" in student:
print("name 키가 존재합니다.")
else:
print("name 키가 존재하지 않습니다.")
# 출력: name 키가 존재합니다.딕셔너리의 생성
딕셔너리(+시퀀스)도 생성-수정-삭제 등의 Life Cycle이 존재함.
구문형식

세트, 리스트, 딕셔너리는 키 불가능
빈 딕셔너리 생성 구문형식

항목의 추가 및 삭제
추가 구문형식

삭제 구문형식

딕셔너리 멤버
| 멤버 | 설명 |
| keys(): tuple | 포함된 모든 키를 반환 |
| values(): tuple | 포함된 모든 값을 반환 |
| items(): tuple | (키, 값) 형태의 투플로 모든 항목을 반환 |
| clear(): None | 모든 항목을 삭제 |
| get(key): value | 키에 해당하는 값을 반환 |
| pop(key): value | 키에 해당하는 값을 반환하고 항목을 삭제 |
| popitem(): tuple | 무작위로 한 (키, 값)을 반환하고 선택된 항목을 삭제 |
딕셔너리 순회
순회(traversal) : 시퀀스에서 각각의 항목을 순서대로 한 번씩만 방문하는 과정
순회형식

데이터 분석 프로그램
"Hamlet_by_Shakespeare.txt" 파일에 포함된 단어가 출현한 횟수를 출력하는 프로그램을 작성하시오

수업시간에 작성한 코드
h_fp = open("/content/Hamlet_by_Shakespeare.txt", "r")
# 파일을 읽기 모드(r)로 열고 파일 객체를 생성함.
word_dict = dict()
# 'word_dict'라는 이름의 빈 딕셔너리를 생성하여 단어의 빈도수를 저장할 것임.
for line in h_fp.readlines():
# 파일의 각 줄을 읽어들이면서 반복함.
for word in line.strip().split():
# 현재 줄에서 불필요한 개행문자를 제거(strip)하고 공백을 기준으로 단어를 분할(split)한 것을 반복함.
word = word.strip(".,:?[]\'\":-").lower()
# 단어에서 불필요한 문장 부호와 기호를 제거하고 모두 소문자로 변환하여 word에 저장함.
# .strip()의 괄호 안에는 여러 특수 문자가 한꺼번에 들어갈 수 있음.
# 이스케이프의 사용
# -- \'는 작은따옴표(') 문자를 특수 문자로 해석
# -- \"는 큰따옴표(") 문자를 특수 문자로 해석
if word_dict.get(word) is not None:
# .get() : 딕셔너리에서 특정 키의 값을 가져오는 메서드
# word_dict라는 딕셔너리에서 word라는 값을 가져와서 존재한다면
count = word_dict[word]
# 해당 word를 count 변수 안에 저장함.
else:
count = 0
# 딕셔너리에 새로운 단어로 등록되는 경우 초기 빈도수를 0으로 설정
word_dict[word] = count + 1
# 단어의 빈도수를 1 증가시킴.
for key in word_dict:
print("[" + key + "] " + str(word_dict[key]) + "회")
# 단어와 해당 단어의 빈도수를 출력함.
h_fp.close()
# 파일 객체를 닫음.
더 간단하고 깔끔하게 수정한 코드
# 키 : 단어 / 값 : 단어가 반복된 횟수
with open("/content/Hamlet_by_Shakespeare.txt", "r") as file:
word_dict = {}
# with문 : 파일을 열고 사용한 후 자동으로 파일을 닫아줌
# as file : open() 함수로 열린 파일 객체를 'file'이라는 변수에 할당하는 역할을 함.
# word_dict라는 딕셔너리를 생성함.
# 반복문1 : 한 줄씩 분리하여 단어로 넣기
for line in file:
words = line.strip().split()
# 파일을 한 줄씩 읽는 과정
# words 안에 개행문자 제거(strip), 단어 단위로 분리(split)
# 반복문2 : 단어의 문자 제거하고 소문자로 통일
for word in words:
word = word.strip(".,:?![]'\":--").lower()
# 정리된 단어의 모음이 words 안에 있음.
# words에서 쓸데없는 문자를 다 제거(strip)하고 소문자로 통일(lower)
# --를 입력하면 -와 --모두 없어짐.
# word가 딕셔너리에 있으면
# word라는 키에 값 1을 하나 더 증가
if word in word_dict:
word_dict[word] += 1
# 없으면 word라는 키를 추가해서 넣고 값 1을 추가
else:
word_dict[word] = 1
for word, count in word_dict.items():
print(f"[{word}] {count}회")
# f-string 형식 사용
# {word}는 현재 단어
# {count}는 해당 단어의 빈도수
# ['키'] '값'회 -> 이런식으로 출력됨.반복문을 2개로 나눠서 쓴 이유는 가독성을 높이고 유지보수를 잘하기 위함임.

데이터 분석 프로그램 개선
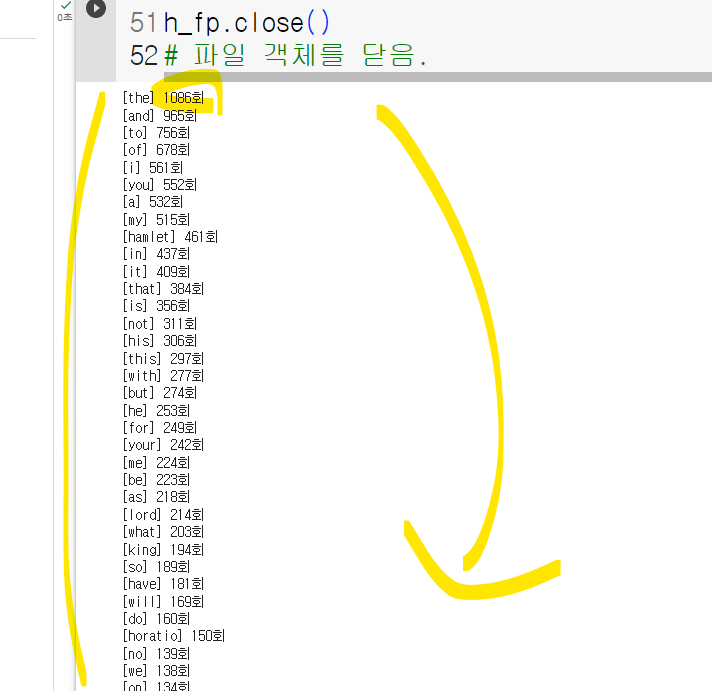
'Hamlet_by_Shakespeare.txt' 파일에 출현 횟수가 100 이상되는 단어와 출력 횟수를 정렬하여 출력하는 프로그램을 작성하시오.
→ 딕셔너리를 정렬할 필요가 있고, 반복횟수(해당 키의 값)이 100회 이상인 조건 걸기

수업시간에 개선한 코드
h_fp = open("/content/Hamlet_by_Shakespeare.txt", "r")
# 파일을 읽기 모드(r)로 열고 파일 객체를 생성함.
word_dict = dict()
# 'word_dict'라는 이름의 빈 딕셔너리를 생성하여 단어의 빈도수를 저장할 것임.
for line in h_fp.readlines():
# 파일의 각 줄을 읽어들이면서 반복함.
for word in line.strip().split():
# 현재 줄에서 불필요한 개행문자를 제거(strip)하고 공백을 기준으로 단어를 분할(split)한 것을 반복함.
word = word.strip(".,:?[]\'\":-").lower()
# 단어에서 불필요한 문장 부호와 기호를 제거하고 모두 소문자로 변환하여 word에 저장함.
# .strip()의 괄호 안에는 여러 특수 문자가 한꺼번에 들어갈 수 있음.
# 이스케이프의 사용
# -- \'는 작은따옴표(') 문자를 특수 문자로 해석
# -- \"는 큰따옴표(") 문자를 특수 문자로 해석
if word_dict.get(word) is not None:
# .get() : 딕셔너리에서 특정 키의 값을 가져오는 메서드
# word_dict라는 딕셔너리에서 word라는 값을 가져와서 존재한다면
count = word_dict[word]
# 해당 word를 count 변수 안에 저장함.
else:
count = 0
# 딕셔너리에 새로운 단어로 등록되는 경우 초기 빈도수를 0으로 설정
word_dict[word] = count + 1
# 단어의 빈도수를 1 증가시킴.
# sorted함수는 key값으로만 정렬이 가능함.
# 그러나 value(빈도) 값으로 정렬해야 됨.
# 그래서 key와 value를 바꿔주는 새로운 딕셔너리를 만들어야 함.
word_r_dict = {v:k for (k,v) in word_dict.items()}
# 리스트에서 가져와서 뒤바꿔서 딕셔너리로 만들라는 말
# ex. 10회 the
word_dict = {k:v for (v,k) in sorted(word_r_dict.items(), reverse=True)}
# 정렬된 걸 다시 바꿔서 원상복귀, 내림차순 정렬로 설정함.
# ex. the 10회, apple 8회
for key in word_dict:
# key의 value(빈도횟수)이 100이상이면 출력
if word_dict[key] >= 100:
print("[" + key + "] " + str(word_dict[key]) + "회")
# 단어와 해당 단어의 빈도수를 출력함.
h_fp.close()
# 파일 객체를 닫음.
더 간단하고 깔끔하게 수정한 코드
with open("/content/Hamlet_by_Shakespeare.txt", "r") as file:
word_dict = {}
for line in file:
words = line.strip().split()
for word in words:
word = word.strip(".,:?![]'\":--").lower()
if word in word_dict:
word_dict[word] += 1
else:
word_dict[word] = 1
sorted_word_dict = sorted(word_dict.items(), key=lambda x: x[1], reverse=True)
# lambda x: x[1]는 입력값 x를 받아서 x[1]을 반환하는 함수
# x : sorted() 함수에서 정렬 기준이 되는 요소인 튜플
# x[1] : 튜플의 두 번째 요소
# sorted() 함수 안 정렬 기준인 'lambda x: x[1]', 즉 두 번째 요소(값, 빈도수)를 기준으로 정렬함.
# sorted_word_dict는 word_dict의 항목을 빈도수에 따라 내림차순으로 정렬한 리스트
for word, count in sorted_word_dict:
if count >= 100:
print(f"[{word}] {count}회")