[코드잇] 데이터 사이언스 기초 - DataFrame 다루기

1. DataFrame 인덱싱
df.loc[row, column], df[column]



df.loc[row, column]
만약 row가 2016인 경우
df.loc[2016, 'SBS'] (O) / df.loc['2016', 'SBS'] (X)
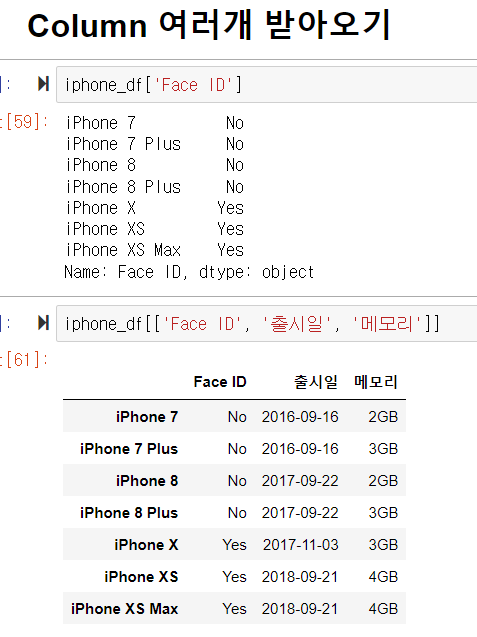
Column에 대한 인덱싱
loc 포함 X (column 이름만 쓰는 방법) : df['JTBC']
loc 포함 O : df.loc[:, 'JTBC']
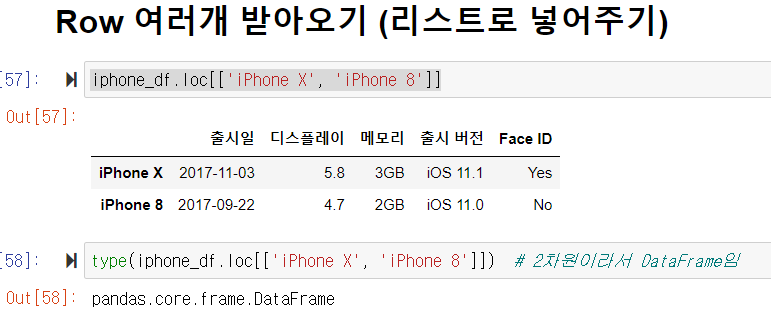
여러 개의 Column에 대한 인덱싱
df[['SBS', 'JTBC']] ---> 대괄호 안에 리스트 '[]'가 들어가야 하니까 대괄호가 2겹임.
'''
방법1 : 파이썬 딕셔너리로 만들어서 합치기
'''
import pandas as pd
spc_df = pd.read_csv('data/spc.csv')
lotte_df = pd.read_csv('data/lotte.csv')
combined_df = pd.DataFrame({
'day': spc_df['요일'],
'spc': spc_df['교통비'],
'lotte': lotte_df['식비']
})
combined_df
'''
방법2 : concat함수 이용
'''
import pandas as pd
spc_df = pd.read_csv('data/spc.csv')
lotte_df = pd.read_csv('data/lotte.csv')
list = [spc_df['요일'], spc_df['교통비'], lotte_df['식비']]
df = pd.concat(list, axis=1, keys=['day', 'samsong', 'hyundee'])
dfaxis=0 (행, 세로방향 합치기)
axis=1 (열, 가로방향 합치기)


DataFrame 조건으로 인덱싱





df.loc[df['SBS'] < df['TV CHOSUN'], ['SBS', 'TV CHOSUN']]
df[df['SBS'] < df['TV CHOSUN']][['SBS', 'TV CHOSUN']]
→ 같은 결과가 나옴.
DataFrame 위치로 인덱싱

DataFrame 인덱싱 요약
| 이름으로 인덱싱하기 | 기본 형태 | 단축 형태 |
| 하나의 row 이름 | df.loc['row4'] | |
| row 이름의 리스트 | df.loc[['row1', 'row2', 'row3']] | |
| row 이름의 리스트 슬라이싱 | df.loc['row3' : 'row5'] | df['row3':'row5'] |
| 하나의 column 이름 | df.loc[:, 'col2'] | df['col2'] |
| column 이름의 리스트 | df.loc[:, ['col2', 'col3', 'col5']] | df[['col2', 'col3', 'col5']] |
| column 이름의 리스트 슬라이싱 | df.loc[:, 'col2':'col5'] |
| 위치로 인덱싱하기 | 기본 형태 | 단축 형태 |
| 하나의 row 위치 | df.iloc[2] | |
| row 위치의 리스트 | df.iloc[[2, 3, 6]] | |
| row 위치의 리스트 슬라이싱 | df.iloc[2:5] | df[2: 5} |
| 하나의 column 위치 | df.iloc[:, 3] | |
| column 위치의 리스트 | df.iloc[:, [3, 5, 7]] | |
| column 위치의 리스트 슬라이싱 | df.iloc[:, 1:2] |
2. 데이터 변형하기
DataFrame에 값 쓰기








DataFrame에 값 추가/삭제



index/column 설정하기



3. 큰 데이터 다루기
큰 DataFrame 살펴보기
sort.values를 하면 정렬된 새로운 데이터프레임 생성
→ inplace=True를 해야 현재 데이터에 반영됨.






큰 Series 살펴보기

4. 강의실 배정 (문제풀이)
1. 수강신청 준비하기
import pandas as pd
import numpy as np
df = pd.read_csv('data/enrolment_1.csv')
# 'status' column 생성
# 각 조건에 해당되는 경우만 'not allowed'로 지정하면 됨
df['status'] = 'allowed'
'''
df.loc[조건1 & 조건2, “column이름”] = “변경 값”
불리언 값 두 개에 & 연산
'''
# 1학년은 information technology 수강 불가
df.loc[ (df['year'] == 1) & (df['course name'] == 'information technology'), 'status'] = 'not allowed'
# 4학년은 commerce 수강 불가
df.loc[ (df['year'] == 4) & (df['course name'] == 'commerce'), 'status'] = 'not allowed'
# 수강생이 5명 미만이면 폐강되어 수강 불가
'''
◆ 방법1 : value_counts로 인덱스 값을 받아서 isin 함수 적용
'''
course_count = df['course name'].value_counts()
df.loc[df['course name'].isin(course_count[course_count < 5].index), 'status'] = 'not allowed'
df
'''
course_counts : Series 형태로 각 과목의 수강생 수가 있음.
course_count < 5 : 각 요소에 대해 5보다 작은지 여부를 판별하는 불리언 Series (True or False 값)
course_count[course_count < 5] : 수강생 수가 5명 미만인 과목들에 해당하는 Series
df['course name'].isin(course_counts[course_counts < 5])
→ isin 함수 안에 불리언 값 series가 있음
df['course name'].isin(course_counts[course_counts < 5].index)
→ isin 함수 안에 인덱스 값(과목명) series가 있음
isin() : 주어진 값과 일치하는 행을 선택하는 역할
→ 인덱스 값을 넣어주어야 해당 인덱스에 맞는 행이 출력됨
'''
'''
◆ 방법2 : value_counts로 수강생 5미만인 과목명 리스트로 만들기 → for 반복문으로 넣어주기
'''
counts = df['course name'].value_counts() # counts < 5는 불리언 값이니까 counts[]로 수를 선택
closed_list = list(counts[counts < 5].index) # 리스트 안에 인덱스(과목명)
for course in closed_list:
# 조건에는 'course name 열에 있는 행의 값 = closed list 안의 값'
df.loc[ df['course name'] == course, 'status'] = 'not allowed'
df
원하는 조건만 변경하는 경우
df.loc[조건1 & 조건2, “column이름”] = “변경 값”
· Series.value_counts()의 리턴 값 : Series
· Series.index의 리턴 값 : Series의 "index 값" (꼭 숫자만은 아님)
· Series.isin(values)
- Whether elements in Series are contained in values.
- 주어진 값과 일치하는 행을 선택하는 역할
- 안에는 set, series, list 등 가능
· list(Series.index)
- Series의 index 값들을 파이썬 리스트로 생성 (바깥에 소괄호)
·조건에 맞는 데이터를 찾아야 하는 횟수가 많을 경우, for문을 활용
https://pandas.pydata.org/docs/reference/api/pandas.Series.index.html
pandas.Series.index — pandas 2.1.0 documentation
next pandas.Series.is_monotonic_decreasing
pandas.pydata.org
2. 강의실 배정하기 Ⅰ
방법1
import pandas as pd
df = pd.read_csv('data/enrolment_2.csv')
# allowed 값 지정
# 'course name'열의 값에 대한 횟수 반환
c = df['course name'].value_counts()
# 강의 이름 목록을 리스트로 생성
'''
c[c>=80]은 c중에서 true값만 출력되는 부분집합임
index함수는 행을 출력함 (타입 :<class 'pandas.core.indexes.base.Index'>)
index를 list로 바꾸어주어야 "리스트가 생성"됨
'''
aud_list = c[c >= 80].index.tolist() # Auditorium ['arts', 'science', 'commerce']
lar_list = c[(c >= 40) & (c < 80)].index.tolist() # Large room
med_list = c[(c >= 15) & (c < 40)].index.tolist() # Medium room
sma_list = c[(c >= 5) & (c < 15)].index.tolist() # Small room
# for 반복문으로 해당하는 "열"에 "값" 넣어주기
for course in aud_list:
df.loc[ df['course name'] == course, 'room assignment'] = 'Auditorium'
for course in lar_list:
df.loc[ df['course name'] == course, 'room assignment'] = 'Large room'
for course in med_list:
df.loc[ df['course name'] == course, 'room assignment'] = 'Medium room'
for course in sma_list:
df.loc[ df['course name'] == course, 'room assignment'] = 'Small room'
# not allowed 값 지정
df.loc[ df['status'] == 'not allowed', 'room assignment'] = 'not assigned'
# 실행
df
방법2
import pandas as pd
df = pd.read_csv('data/enrolment_2.csv')
# allowed 값 지정
# 과목 리스트 만들기
c = df['course name'].value_counts()
aud_list = c[c >= 80].index # Auditorium
lar_list = c[(c >= 40) & (c < 80)].index # Large room
med_list = c[(c >= 15) & (c < 40)].index # Medium room
sma_list = c[(c >= 5) & (c < 15)].index # Small room
# 강의실 할당
df.loc[df['course name'].isin(aud_list), 'room assignment'] = 'Auditorium'
df.loc[df['course name'].isin(lar_list), 'room assignment'] = 'Large room'
df.loc[df['course name'].isin(med_list), 'room assignment'] = 'Medium room'
df.loc[df['course name'].isin(sma_list), 'room assignment'] = 'Small room'
# not allowed 값 지정
# not allowed 값에 강의실이 배정되는 오류가 발생해서 'not assigned'를 가장 마지막에 해준다
df.loc[df['status'] == 'not allowed', 'room assignment'] = 'not assigned'
# 테스트 코드
df
방법3
import pandas as pd
import numpy as np
df = pd.read_csv('data/enrolment_2.csv')
# 80명 이상의 학생이 수강하는 과목은 “Auditorium”에서 진행
c = df['course name'].value_counts()
df.loc[ df['course name'].isin(c[c >= 80].index), 'room assignment'] = 'Auditorium'
# 40명 이상, 80명 미만의 학생이 수강하는 과목은 “Large room”에서 진행
df.loc[ df['course name'].isin(c[(c >= 40) & (c < 80)].index), 'room assignment'] = 'Large room'
# 15명 이상, 40명 미만의 학생이 수강하는 과목은 “Medium room”에서 진행
df.loc[ df['course name'].isin(c[(c >= 15) & (c < 40)].index), 'room assignment'] = 'Medium room'
# 5명 이상, 15명 미만의 학생이 수강하는 과목은 “Small room”에서 진행
df.loc[ df['course name'].isin(c[(c >= 5) & (c < 15)].index), 'room assignment'] = 'Small room'
# 폐강 등의 이유로 status가 “not allowed”인 수강생은
# room assignment 또한 “not assigned”가 되어야 함.
df.loc[ df['status'] == 'not allowed', 'room assignment'] = 'not assigned'
df
오류난 이유
import pandas as pd
df = pd.read_csv('data/enrolment_3.csv')
c = df['course name'].value_counts()
print(c)
'''
arts 158
science 123
commerce 105
english 56
education 41
management 38
nursing 36
chemistry 33
'''
print(type(c))
# <class 'pandas.core.series.Series'>
print(c[c>80]) ---> c의 부분집합 (c중에서 c>80인 것들 추출)
'''
arts 158
science 123
commerce 105
'''
print(type(c[c>80]))
# <class 'pandas.core.series.Series'>
print(type(c>80))
# <class 'pandas.core.series.Series'>df.loc[ c[c>80], 'course name']
'''
158 commerce
123 management
105 civil engineering
Name: course name, dtype: object
'''위에서 df.loc[c[c>80], 'course name']을 입력하면
c[c>80]의 arts, science, commerce (인덱스 부분)이 아닌 값 부분(158, 123, 105)이
df.loc[ row, column ]에 따라
df에서 행의 인덱스(158, 123, 105)로 들어가는 것을 볼 수 있음
그래서 df.loc로 접근하는 것이 잘못 되었음.
2. 강의실 배정하기 Ⅱ
import pandas as pd
df = pd.read_csv('data/enrolment_3.csv')
c = df.loc[df['status'] == 'allowed', 'course name'].value_counts()
# 리스트 생성
aud_list = c[c >= 80].index.tolist() # Auditorium ['arts', 'science', 'commerce']
lar_list = c[(c >= 40) & (c < 80)].index.tolist() # Large room
med_list = c[(c >= 15) & (c < 40)].index.tolist() # Medium room
sma_list = c[(c >= 5) & (c < 15)].index.tolist() # Small room
# 배정
for i in range(len(aud_list)):
df.loc[ df['course name'] == sorted(aud_list)[i], 'room assignment'] = f'Auditorium-{i + 1}'
for i in range(len(lar_list)):
df.loc[ df['course name'] == sorted(lar_list)[i], 'room assignment'] = f'Large-{i + 1}'
for i in range(len(med_list)):
df.loc[ df['course name'] == sorted(med_list)[i], 'room assignment'] = f'Medium-{i + 1}'
for i in range(len(sma_list)):
df.loc[ df['course name'] == sorted(sma_list)[i], 'room assignment'] = f'Small-{i + 1}'
# 열 이름 변경
df.loc[df['status'] == 'not allowed', 'room assignment'] = 'not assigned'
# 열 이름 변경
df.rename(columns = {'room assignment':'room number'}, inplace=True)
# 테스트 코드
df코드는 잘 작동하는데 방 이름 옆에 뜨는 숫자(Medium-숫자)가 틀려서 확인해봄.
변수 c정의할 때 status가 allowed인 조건을 빼먹음.
왜냐하면 data 중에 폐강인원(5명 미만)이 아닌데도 not allowed인 것들이 있어서 이것을 고려했어야 했음.