
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- HTML
- 코드잇
- 꿀단집
- 항해99
- 유노코딩
- 코딩테스트
- 방송대
- 코딩테스트준비
- JavaScript
- 중간이들
- 파이썬
- TiL
- Azure
- node.js
- Python
- 방송대컴퓨터과학과
- 프로그래머스
- 99클럽
- nestjs
- CSS
- mongoDB
- 데이터베이스시스템
- 엘리스sw트랙
- 데이터분석
- 오픈소스기반데이터분석
- 개발자취업
- Git
- 클라우드컴퓨팅
- 파이썬프로그래밍기초
- aws
- Today
- Total
배꼽파, 오늘도 배꼽 대신 데이터를 판다
[엘리스sw] MongoDB - 개요, CRUD, 쿼리 연산자, 고급 활용 기능 본문

◆ MongoDB 개요
◆ CRUD
◆ 쿼리 연산자
◆ 고급 활용 기능
◆ MongoDB 개요
MongoDB 명령어
DB 접속
use myDatabase
정보 저장
db.initialCollection.insertOne({hello: "world"})
정보 확인
db.initialCollection.find()NoSQL
NoSQL의 특징
· 질의 명령어가 SQL이 아니다
· 정보의 형식을 미리 정하지 않는다
NoSQL DBMS
· NoSQL (Not Only SQL) :
- 전통적인 관계형 데이터베이스보다 덜 제한적인 일관성 모델을 제공하는 DB
- 기존 RDBMS가 일관성 모델 때문에 가질 수 없었던 확장성, 유연성, 고성능, 고기능성을 확보함.
· DBMS (Database Management System, DB) : 데이터를 저장하고 관리하는 시스템
대표적인 관계형 데이터베이스 제작시기: 1990년대 이전
- MySQL : 1995년 출범
- PostgreSQL : 1996년 출범
- OracleDB : 1979년 출범
대표적 NoSQL DB 제작시기: 2009년 이후
- MongoDB : 2009년 출범
- elasticsearch : 2010년 출범
- redis : 2009년 출범
1990년대(RDBMS)와 2009년(NoSQL)
2007년 아이폰 등장
2010년 이후 인터넷이 급속도로 확장됨.
전통적 RDBMS 규칙
- ACID 원칙을 준수
- 2차원의 테이블 형태
- SQL을 통한 질의
2010년 이후 서버에 요구되는 정보 처리량의 급속한 증가
정보 처리량을 늘리려면 규칙을 깨야함.
RDBMS : 안정성에 중점
NoSQL : 확장성과 성능 최적화에 특화됨.
- MongoDB : 범용적 활용
- Redis : 캐싱 특화
- elasticsearch : 전문 검색 특화
MongoDB 소개 및 분산 컴퓨팅
MongoDB 사용처
- PC방 관리시스템에 도입 : RIOT Games
- 개인화된 추천 서비스에 도입 : 카카오톡
- 알림 서비스에 도입 : FLO
- 그 외 각종 서비스 : 카카오페이, 카카오페이지, 카카오
왜 MongoDB는 배우고 싶은 기술일까?
- 현대적 설계로 고성능을 내면서 동시에 많은 기능과 안정화가 이루어진 다목적 DB
- 인터넷의 부상으로 서버의 요구 처리량이 증가함.
ex) 카카오톡 : 하루 평균 송수신 메시지 110억건 (초당 평균 13만건의 송수신)
MongoDB의 현대적 설계
- 과거에는 하나의 DBMS로 처리하는 상황이 빈번했음.
ex. MySQL은 서버 여러 대에서 돌리는 것을 고려하지 않음. - 기존 RDBMS는 하나의 인스턴스에서 작동하는 것이 기본값
- 요즘은 처리할 데이터양이 많아서 분산 컴퓨팅이 빈번함.
현재적 DBMS는 분산 컴퓨팅을 하는 것이 기본값
오히려 서버 1대에서 사용할 때 불편하다고 느낄 수 있음.
분산 컴퓨팅의 방식
MongoDB에서 지원하는 분산컴퓨팅 : 복제, 샤딩
| 복제 (replica) | 샤딩 (sharding) |
| 복사하여 저장하는 방식 | 나누어 저장하는 방식 |
| 안정성을 높이기 위한 방식 원본 서버가 망가져도 정상 서비스 가능 |
성능을 향상하기 위한 방식 읽기, 쓰기 성능 향상 가능 |
분산 컴퓨팅 관련 MongoDB 주의점
단일 인스턴스 DBMS에서 만약 쓰기 작업을 하다가 서버가 갑자기 꺼진다면?
- MongoDB : 데이터가 의도치 않게 중간 상태로 저장될 수 있다
(기본값임, 안전 수준 높이면 이렇게 안 됨) - MySQL : 데이터가 항상 저장 완료하거나 저장 실패한 상태로만 존재
Why?
- MongoDB는 분산 컴퓨팅을 하는 것을 가정하고 쓰기 기본 설정이 되어 있다.
- Write-Concern, Read-Concern 설정을 알아야 제대로 사용 가능하다.
JS 친화적 MongoDB
분산 컴퓨팅 기본값 설정의 문제점
→ 입문이 너무 어렵다!
MongoDB 탄생 당시 신생 JS 엔진이 등장함.
2008년 JS 속도를 획기적으로 향상시킨 V8엔진 등장
2008년 Chrome의 부상
2009년 백엔드 개발이 가능한 NodeJS 등장
V8엔진의 성능향상으로 인한 웹 개발자의 대규모 업종 전환
MongoDB도 이런 대세를 활용하여 SQL을 몰라도 개발 가능한 V8엔진의 JS 기반 쉬운 DBMS를 표방함.
내부 명령어가 JS로 구성되어 있음.
db.initialCollection.find()
JSON과 비슷한 BSON 자료구조
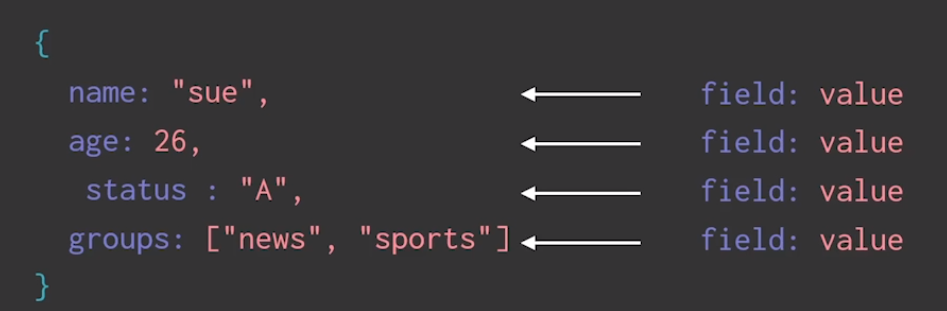
스키마가 없는 방식
변수를 저장하는 것처럼 대입해서 집어넣는 방식임.
MongoDB가 JS를 사용해서 얻은 특징
- 웹 개발자에게 쉬운 입문이 가능하다
- BSON 자료형 사용
- 내부 명령어를 JS 형식으로 사용 (내부는 C언어로 개발됨)
MongoDB 활용
| MySQL, PostgreSQL, ORACLE | MongoDB |
| 적어도 25년간 유지보수된 기술 다양한 개발자와 관련 문서 |
개발된 지 10년된 기술 이제 어느정도 안정성이 갖춰짐 |
MongoDB의 특장점
- JS에 친화적이다
- 성능 확장이 쉽다
- 높은 성능을 낼 수 있다
- 유연한 구조로 저장할 수 있다
- 다양한 자료형을 지원한다
ex. 지도, 좌표
사용하면 좋은 경우
1. JS 기반 프로젝트
| React, node.js, MongoDB | Firebase → MongoDB |
| - 프로젝트 언어를 JS로 통일시키고자 할 때 - 정보 변환 없이 전달 가능 |
- 기존의 JSON 방식의 DB에서 좀 더 많은 기능과 성능이 필요할 때 - 입문용 DB에서 실전용 DB로 전환 |
2. 저장할 정보의 형태가 자주 변경되는 경우
| 파일럿 프로젝트 | 비 정형화된 정보를 전산화 |
| - 앞으로 몇 명이 이용할지 예측이 안 되는 프로젝트 - 한참 개발 중이고 상황에 따라 데이터 구조가 쉽게 바뀔 수 있는 신규 프로젝트 (기존 RDBMS는 테이블이 계속 바뀜) - 샤딩으로 손쉽게 확장 가능 |
- 각종 예외사항이 적혀 있는 수기로 작성된 과거의 주문 정보 - 로그 데이터 형식의 정보를 저장할 때 (형식이 구제척으로 정해져있지 않음) - 정보를 정형화하기에 어려운 경우 |
사용하면 안 좋은 경우
| 안정성보다 높은 성능이 필요한 경우 | 안정성보다 높은 성능이 필요할 때 |
| NoSQL이 기존 DBMS보다 수십배는 더 높은 성능을 가짐. | ex. 카카오 모빌리티의 지도 정보, SNS 정보 저장 |
→ 높은 성능보다 안정성, 무결성이 중요한 경우 오랜 세월 검증된 전통적 RDBMS를 활용하는 것이 유리함.
◆ CRUD
MongoDB 기본 구조
- 3단 구조 : 데이터베이스, 컬렉션, 도큐먼트
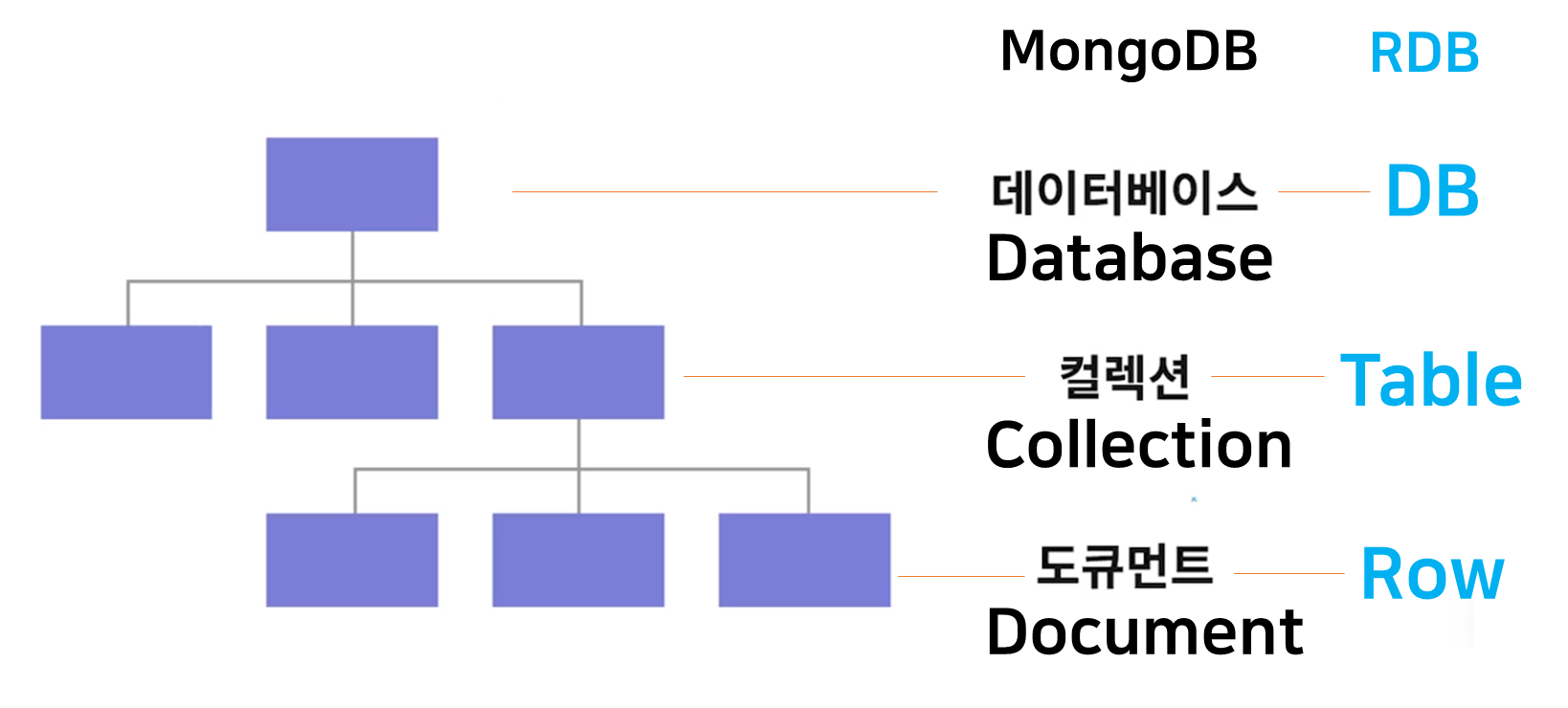
BSON 구조
JSON(Javascript Object Notation)과 유사한 BSON 구조로 정보를 저장
해시맵과 유사한 형식의 구조
Pymongo 소개
pymongo는 mongoDB를 사용할 수 있게 도와주는 파이썬 모듈

db = connection.get_database("testDB")
collection = db.get_collection("testCollection")
collection.insert_one({ "hello": "world" })컬렉션에 도큐먼트 저장. 만약 컬렉션이 없다면 자동으로 생성됨.
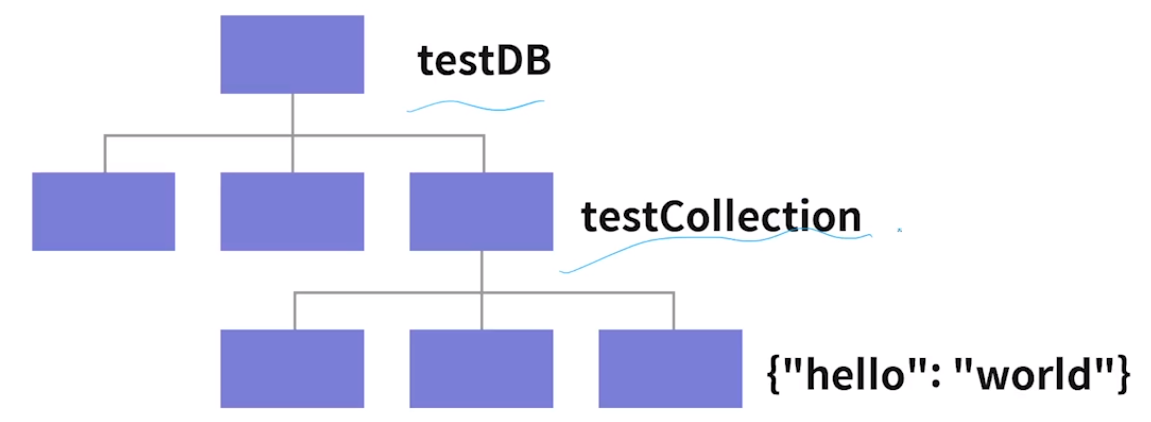
데이터베이스, 컬렉션, 도큐먼트 확인하기
Python 코드
# 데이터베이스 목록 조회
print(connection.list_database_names())
# ['admin', 'config', 'local', 'testDB']
# 컬렉션 목록 조회
print(db.list_collection_names())
# ['testCollection']
# pprint로 도큐먼트 목록 조회
pprint(list(collection.find()))
# [{'_id': ObjectId('...'), 'hello': 'world'}]BSON 데이터 타입

| NULL | Null | 아무것도 없음 |
| Undefined | Undefined | 정의되지 않음 |
| Double / Integer | 실수형/정수형 | 123.42 / 12 |
| String | 문자열 | "hello" / 'hello' |
| Object | 객체 | {field: "value"} |
| Array | 배열 | [1, 2, {hi: "hello"}] |
| Boolean | 불린 | true / false |
| Date | 날짜 |  |
| ObjectId | ObjectId |  |
ObjectId의 구성
ObjectId
- MongoDB에서 각 Document의 primary key의 값으로 사용함.
- 각각의 document값을 구분할 수 있는 값으로 사용됨(유일한 값)
- 각 document가 유일한 값을 가져야 컴퓨터가 구분하기 쉬워짐.
- 삽입, 복제할 때의 상황 등을 확장성을 염두해두고 설계함.

| 유닉스 시간 | Unix epoch 이후 초 단위로 측정된 ObjectId의 생성을 나타내는 4바이트 타임스탬프 값 |
| 기기 id | 프로세스당 한 번 생성 되는 5바이트 임의 값 |
| 프로세스 id | 프로세스당 한 번 생성 되는 5바이트 임의 값 |
| 카운터 | 만약 시간, 기기, 프로세스가 같아도 저장된 값들은 매번 증가하는 카운터로 구분할 수 있음. |
https://www.mongodb.com/ko-kr/docs/manual/reference/method/ObjectId/
ObjectId() — MongoDB 매뉴얼
문서 홈 → 애플리케이션 개발 → MongoDB 매뉴얼 ObjectId( )새 객체 ID를 반환합니다. 12바이트 객체 ID는 다음으로 구성됩니다.Unix epoch 이후 초 단위로 측정된 ObjectId 생성을 나타내는 4바이트 타임스
www.mongodb.com
Pymongo에서 사용하기
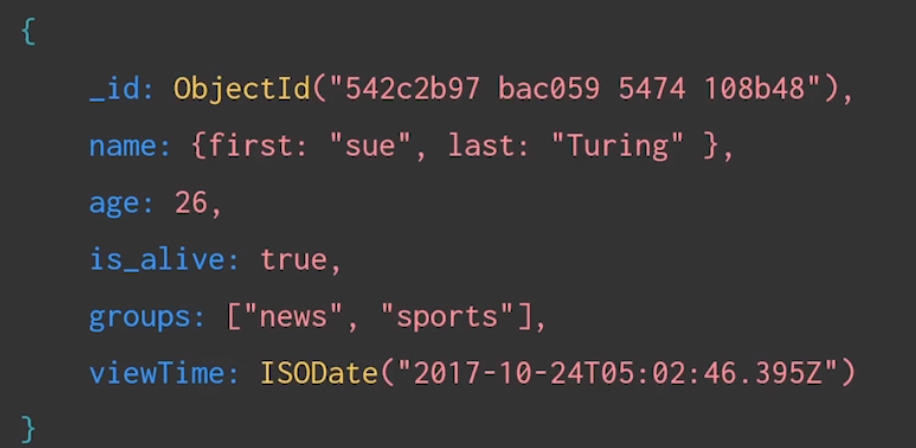
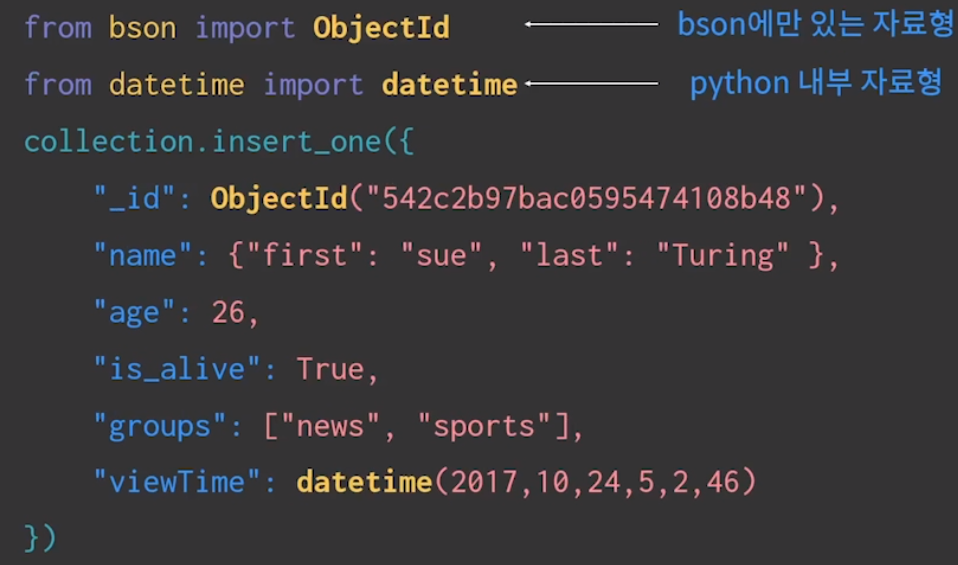
파이썬 내부에서는 BSON 자료형을 data type으로 표현할 수 없음.
→ bson에만 있는 자료형과 python 내부 자료형을 섞어서 사용함.
- 모든 도큐먼트에는 _id필드가 있다.
- 한 컬렉션에 _id 필드를 같게 설정할 수 없다.
- _id필드 값을 따로 설정하지 않으면 ObjectId 객체가 저장된다.
- 따로 설정한 경우 해당 값으로 저장할 수 있다.
- 자동 생성된 ObjectId 객체는 항상 서로 다른 값을 가지도록 설계되었다.
- 도큐먼트를 구분하기 위한 필드를 primary Key라고 한다.
도큐먼트 생성
도큐먼트를 보기 좋게 출력하기
from pprint import pprint
pprint({ BSON document })
- pprint : pretty print 의미를 가진 명령어
컬렉션에 도큐먼트 삽입하기
# pymongo 모듈 불러오기
import pymongo
# MongoDB에 대한 연결 설정
connection = pymongo.MongoClient("mongodb://localhost:27017/")
# 'testDB' 데이터베이스 선택 혹은 생성
db = connection["testDB"]
# 'testDB' 데이터베이스 내에서 'testCollection' 생성
collection = db["testCollection"]
# document 생성 (hello 필드에 값 'world'를 지정)
collection.insert_one({ "hello": "world" })
필드 이름은 있지만 값을 지정하지 않으면 오류가 발생함.
collection.insert_one({ "example_field" })
명시적으로 key, value값을 지정해주어야 함.
collection.insert_one({ "example_field": None }){ "_id": ObjectId("..."), "example_field": null }
컬렉션에 하나의 도큐먼트 삽입하기
from pprint import print
result = collection.insert_one(
{ document}
)
# 입력된 도큐먼트의 _id값
print(result.inserted_id) // 609fce475cfb9675580a6efc
print(result.inserted_id) // ObjectId('609fce475cfb9675580a6efc')
컬렉션에 다수의 도큐먼트 삽입하기
result = collection.insert_many(
[ { document }, { document }, ... ]
)
print(result.inserted_ids)
웹 서버에서 도큐먼트 생성 예시

만약 게시글을 작성하는 웹 서버를 구현한다고 가정하면 다음과 같은 로직을 만들 수 있음.
ex. 결제정보 저장 후 결제완료 내역의 objectId값을 불러와서 장바구니 내역 지우기
도큐먼트 검색 기초
컬랙션에서 도큐먼트 검색하기
find
- 컬랙션 내에 query 조건에 맞는 다수의 도큐먼트를 검색함
result = collection.find(
{ query },
{ projection }
)
print(result)
print(list(result))# Cursor를 반환
<pymongo.cursor.Cursor object at 0x7fc6b31659b0>
# list로 내용물을 불러올 수 있다
[ { document }, { document }, ... ]
커서
- 커서는 쿼리 결과에 대한 포인터
- 도큐먼트의 위치정보만을 반환하여 작업을 효율적으로 만들어준다
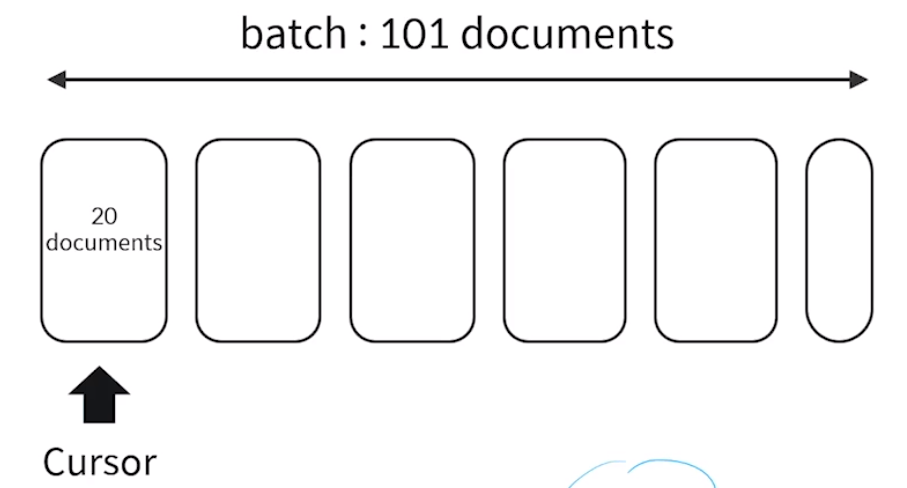
반환되는 다큐먼트가 많으면 서버에 과부하가 걸리니까 이걸 우려해서 커서 정보만 넘겨줌.
그 중 일부만 불러와서 처리하면 됨.
커서에서 도큐먼트 불러오는 부분
result = collection.find(
{ query }
)
print(list(result))
for document in result:
print(document)# list로 내용물을 한번에 불러올 수 있다
[ { document }, { document }, ... ]
→ 이런 상황은 권장하지 않음. 왜냐하면 몇 개인지 모르는데 다 불러오면 안 됨.
# for문으로 내용물을 하나씩 처리할 수 있다
{ document }
{ document }
...
쿼리
- 원하는 정보를 걸러내기 위한 깔데기
- 검색하고자 하는 내용을 쿼리로 표현할 수 있어야 함.
(SQL의 WHERE절과 유사함)
{"field": value, "field": value, ...}Query는 그 field에 맞는 value 값으로 필터링 함.
find문 예시

projection
- projection은 그 field를 보여줄 지 말지를 알려준다
- boolean이 true이면 해당 field를 표현하고, false면 field를 제외한 결과를 출력한다.
{"field": boolean, "field": boolean, ...}
projection 예시

현재 password는 보이지 않음. username 필드만 보여줌.
projection의 잘못된 예
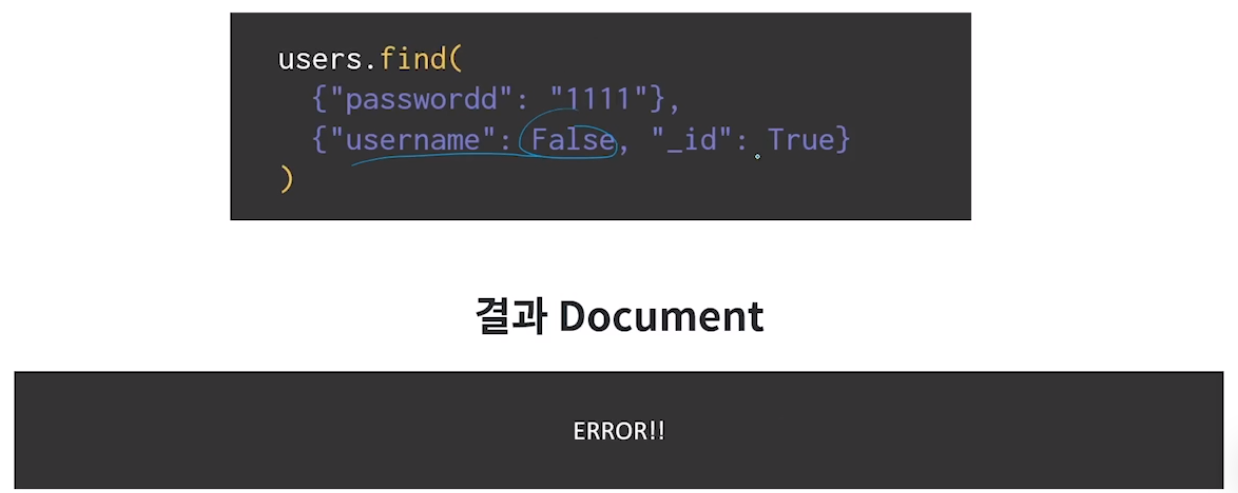
이렇게 username과 _id값의 boolean이 서로 다를 경우 오류가 남.
그럼 password는 어떻게 할지 모르니까.
도큐먼트 수정
하나의 도큐먼트를 찾아 수정하기
- query로 검색하고, update에 변경할 사항을 적는다
- update_one: 찾은 결과물이 여러 개면 1개만 찾아서 수정함.
- update_many: 찾은 결과물을 모두 수정함(1개든 여러 개든).
result = collection.update_one(
{ query },
{ update },
upsert:Boolean
)
print(result.matched_count)
print(result.modified_count)# 찾은 도큐먼트 수
1
# 변경된 도큐먼트 수
1
다수의 도큐먼트를 찾아 수정하기
- query로 검색하고, update에 변경할 사항을 적는다
result = collection.update_many(
{ query },
{ update },
upsert:Boolean
)
print(result.matched_count)
print(result.modified_count)# 찾은 도큐먼트 수
12
# 변경된 도큐먼트 수
5
특정 field값을 업데이트 하기

inventory.update_one(
{"item": "canvas"},
{"$set": {"qty": 10}}
)canvas라는 item을 찾아서 qty라는 필드 값을 10으로 설정하고 싶음.

특정 field를 제거하기
inventory.update_one(
{"item": "canvas"},
{"$unset": {"qty": True} }
)
해당되는 document가 없다면 새로 추가하기
inventory.update_one(
{"item": "flash"},
{"$set": {"size": {"h": 10, "w": 8},
"status": "F"} }, True
)
- upsert가 true인 경우 : 해당 결과가 없다면 값을 생성해서 값을 집어 넣음.
- 집어넣는 필드와 value는 해당 쿼리 정보와 넣으려고 했던 value값임.
이외에도 사용할 수 있는 update 연산자


MongoDB에서 연산자는 꼭 '$' 표시를 앞에 붙임.
$는 기능을 의미하는 연산자임.
도큐먼트 삭제
하나의 도큐먼트를 찾아 삭제하기
- delete_one : query로 검색하고 첫번째 도큐먼트를 삭제
result = collection.delete_one(
{query}
)
print(result.deleted_count)# 삭제된 도큐먼트 수
1
다수의 도큐먼트를 찾아 삭제하기
- delete_many : query로 검색하고 다수의 도큐먼트를 삭제
result = collection.delete_many(
{query}
)
print(result.deleted_count)# 삭제된 도큐먼트 수
12
특정 field 값을 업데이트 하기


쿼리 연산자
쿼리의 구조
SQL 쿼리 vs MongoDB 쿼리
SQL 쿼리의 모습
SELECT * FROM table WHERE column="value"
mongoDB 쿼리의 모습
collection.find({"field": "value"}, {})BSON 형식으로 쿼리를 표현하다보니 많이 헷갈림.
쿼리의 형식
기본적으로 쿼리는 필드가 가장 바깥에 있고, 안쪽에 연산자가 들어감.
{ <field>: {<operator1>: <value>, <operator2>: <value>}, <field>: ...}예시)
{ "height": {"gte": 175, "$lte": 180}, "width": {"gte": 60} }
예외적으로 $or, $and, $nor 세 개의 연산자는 가장 바깥쪽에서 쓰임.
{
<$or, $and, $nor>: [<query>, <query>, ...],
<field>: {<operator1>: <value>, <operator2>: <value>, <field>: ... }
}예시)
{ "$or": [ { "status": "A" }, { "qty": { "$lt": 30 } } ] }정해진 형식을 지키지 않은 쿼리는 사용될 수 없음.
{"필드": {"연산자": "값"}} (O)
{"필드": {"필드": "값"}} (X)잘못된 예
{"name": {"first": 'Karoid', "last": 'Jeong'}}올바른 예
{"name.first": 'Karoid', "name.last": 'Jeong'}출처: 맛있는 몽고디비
점 표기법
- BSON 내부의 Object에 접근하기 위한 방법
객체 내부로 접근하기
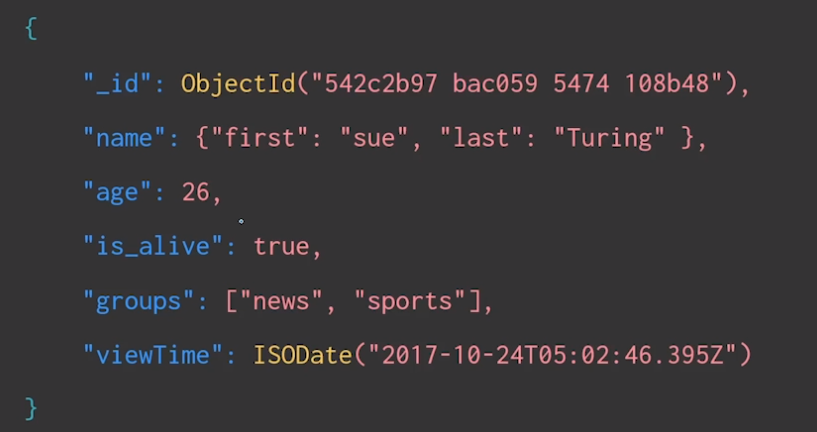
만약 name 안의 first 값을 조회하려면 어떻게 할까?
→ 점 연산자로 내부에 접근할 수 있다
잘못된 쿼리
{"name": {"first": 'sue'}}
올바른 쿼리
{"name.first": 'sue'}
배열의 요소에 접근하기

배열의 첫 번째 요소로 news 값을 값는 도큐먼트를 찾고 싶다면?
잘못된 쿼리
{"groups": ["news"]}
올바른 쿼리
{"groups.0": "news"}비교 연산자
비교 연산자 종류
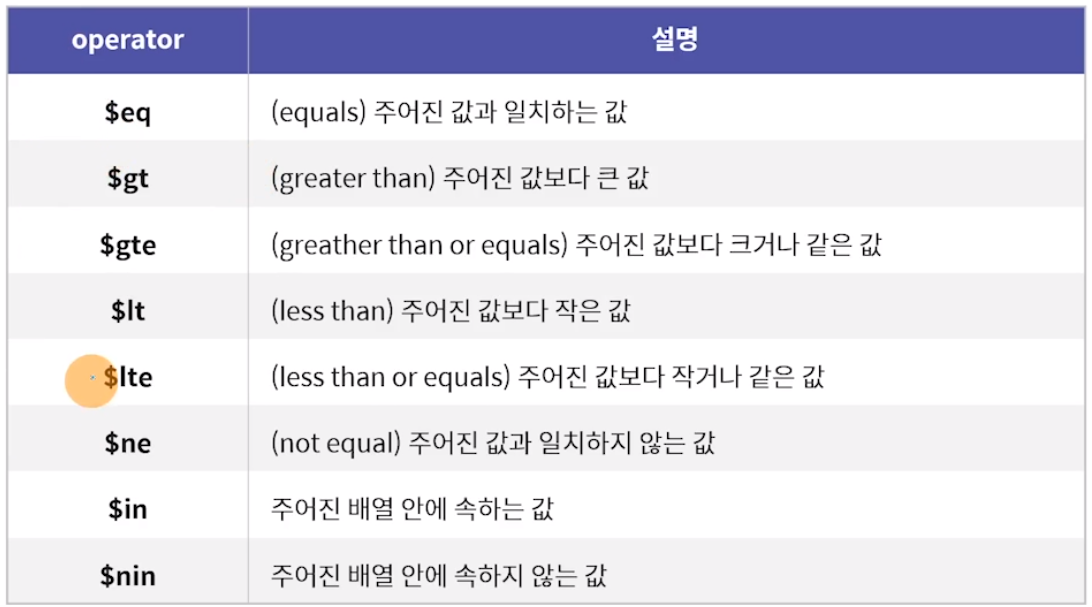
대소 비교 쿼리 예시
좋아요 수가 10 초과 30 미만인 도큐먼트 검색
articles.find( { "likes": { "$gt": 10, "$lt": 30 } } )좋아요 수가 10 이상 30 이하인 도큐먼트 검색
articles.find( { "likes": { "$gte": 10, "$lte": 30 } } )
숫자외의 다른 타입 비교
- 문자열 : 사전순으로 대소비교 할 수 있음.
- 알파벳 순 : 알파벳 순이 빠른 것부터 앞으로 옴.
- 언어가 다른 문자열들 : binary로 변환해서 더 큰 값 - 배열 : 원소 인덱스 같은 것끼리 순서대로 비교
- 객체 : key의 값을 순서대로 비교

포함 쿼리 예시
수량이 5 또는 15인 아이템 도큐먼트
inventory.find( { "qty": { "$in": [ 5, 15 ] } } )태그가 정규표현식 ^be 또는 ^st에 일치하지 않는 도큐먼트
inventory.find( { "tags": { "$nin": [
re.compile("^be"),
re.compile("^st")
]} } )논리 연산자
논리 연산자 종류

연산자의 위치 주의
게시글 중 제목이 article01이거나 작가가 Alpha인 도큐먼트
articles.find({ "$or": [ { "title": "article01" }, { "writer": "Alpha" } ] })
좋아요 수가 11이하가 아닌 도큐먼트
articles.find({ "likes": { "$not": { "$lte": 11 } } })
and 연산자는 사실 쓸 일이 많지 않음.
두 쿼리는 서로 같은 의미를 가짐.
col.find({"$and": [
{"qty": {"$gt": 10}},
{"qty": {"$lt": 100}}
]})col.find({ "qty": {"$gt": 10, "$lt": 100} })
복합적인 논리 연산자의 사용

문자열 연산자
Evaluation Query 중에서 문자열 연산자인 regex와 text가 자주 쓰임

정규표현식 : 특정 패턴의 문자열을 검색하기 위한 수식
{ <field>: { "$regex": 'pattern', "$options",'<options>' } }
정규표현식 예시
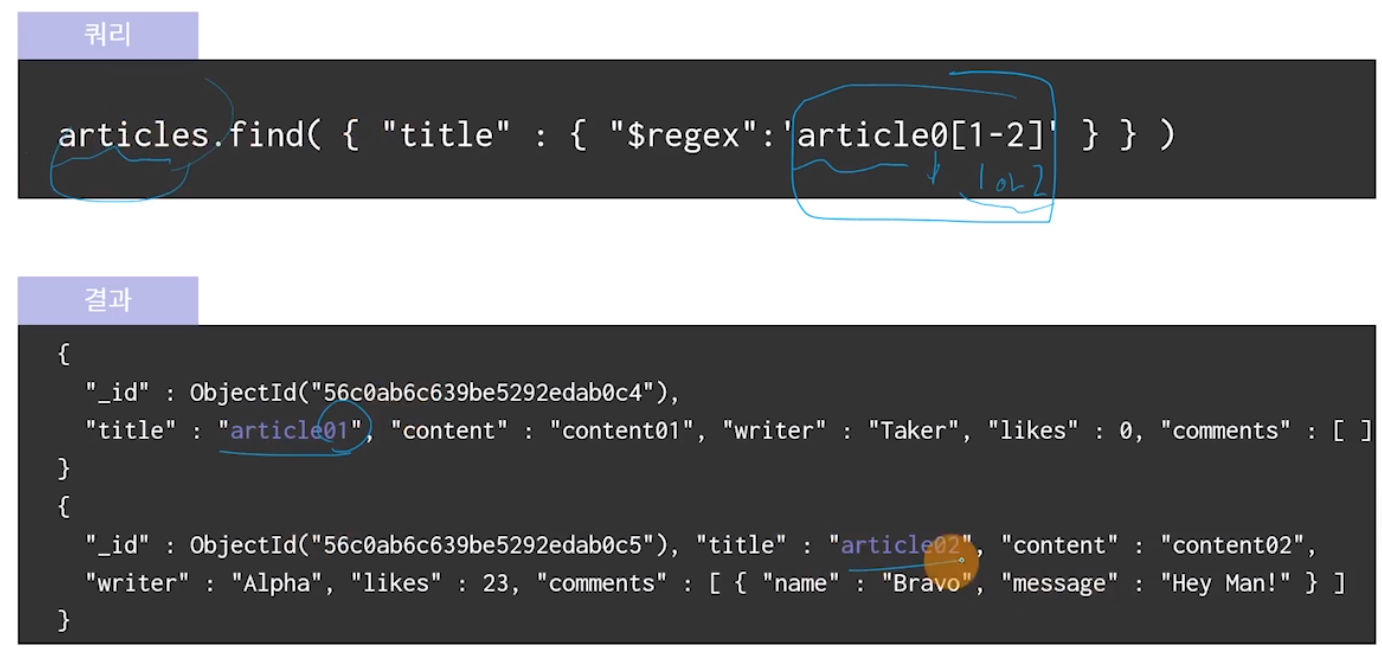
article0 뒤에 1또는 2가 나오라는 의미임.
Text 연산자 (전문검색 연산자)
컬렉션당 하나만 만들 수 있는 문자열 인덱스에서만 작동함
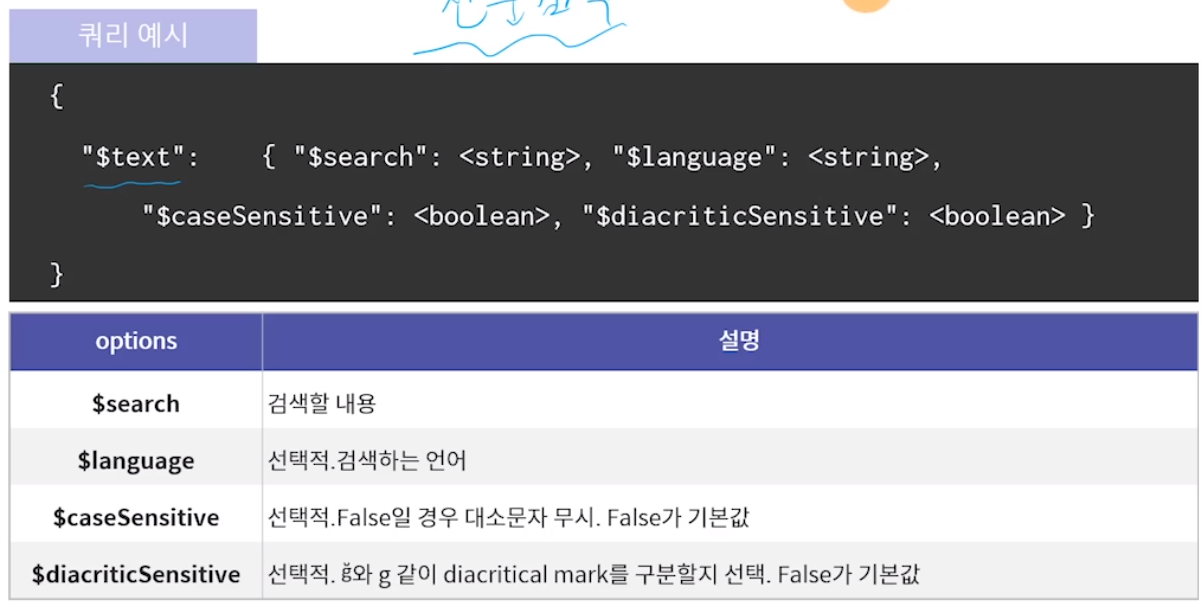
문자열 인덱스 설정
collection.create_index([('field', pymongo.TEXT)], default_language='english')
컬렉션당 하나만 만들 수 있는 문자열 인덱스에서만 작동함.
안타깝게도 한국어는 문자열 인덱스로 지원하지 않음.
Text 연산자 예시 : 한 단어

Text 연산자 예시 : 여러 단어

형이 바뀌어도 원하는 동사를 찾을 수 있음.
Text 연산자 예시 : 구절을 검색
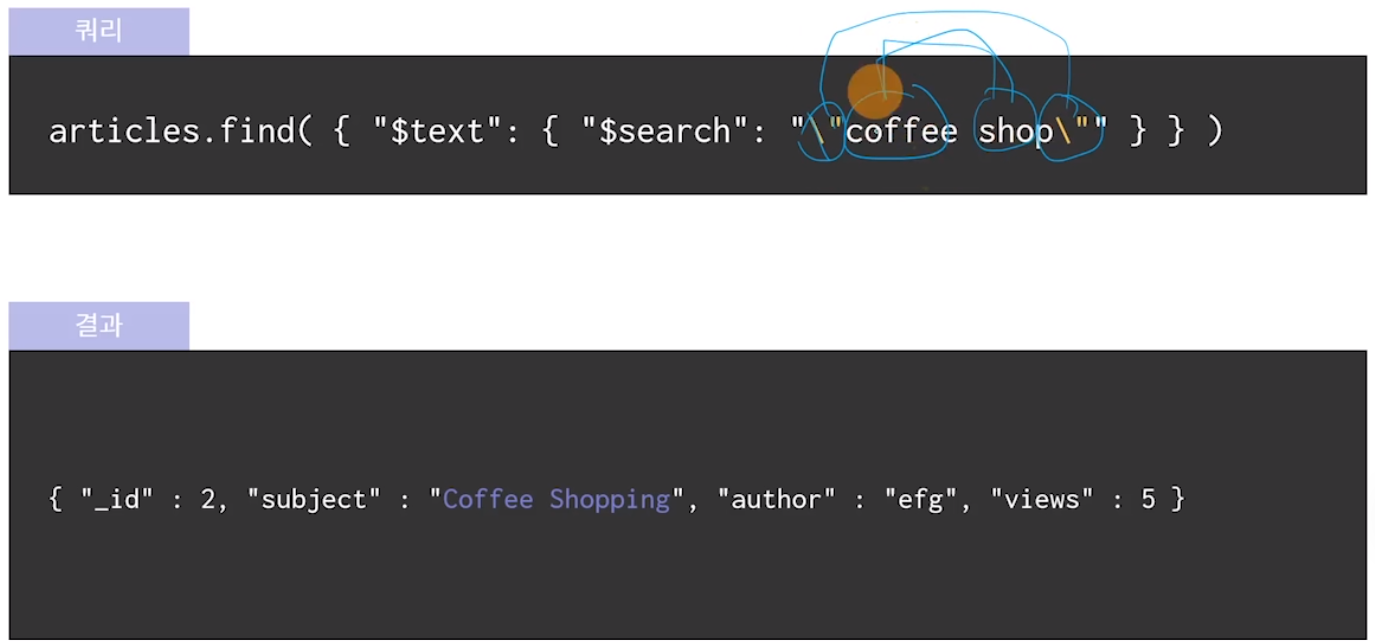
coffee와 shop 단어가 모두 포함된 document를 불러옴.
배열 연산자
도큐먼트에서 배열의 의미
inventory.find({"tags":"school"})
단순히 문자열 'school'뿐만 아니라 배열 속에 'school'이 있는 값도 검색됨.

배열 연산자 종류

$all 연산자
배열 속 모든 값을 포함하는 Document를 찾는다
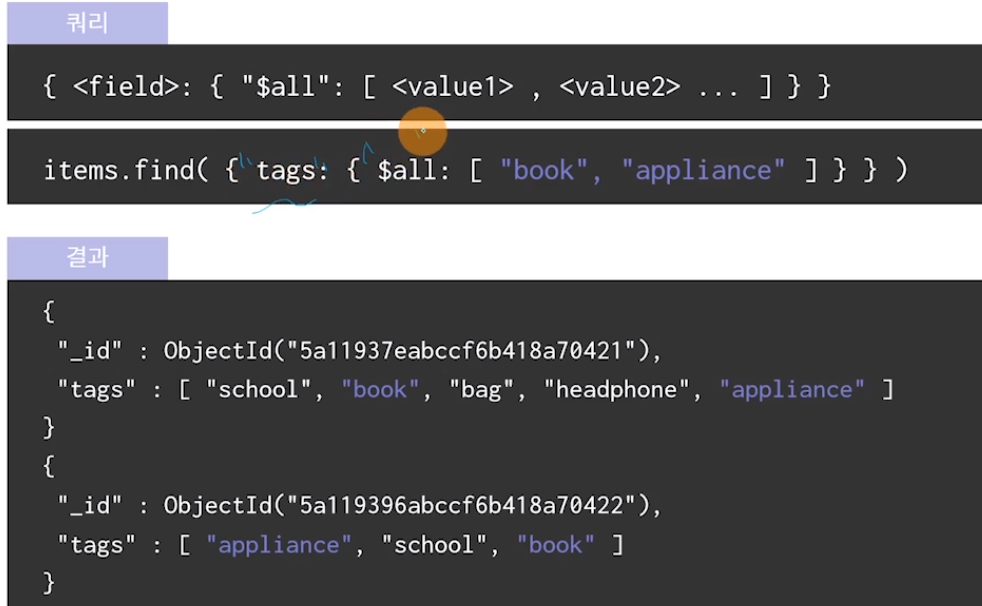
만약 {"tags": ["book", "appliance"]}라고 쓰면 정확히 안에 book과 appliance만 있는 배열 document만 불러와짐.
$elemMatch 연산자
해당 field가 query들을 모두 만족하는 값을 갖는 도큐먼트를 검색
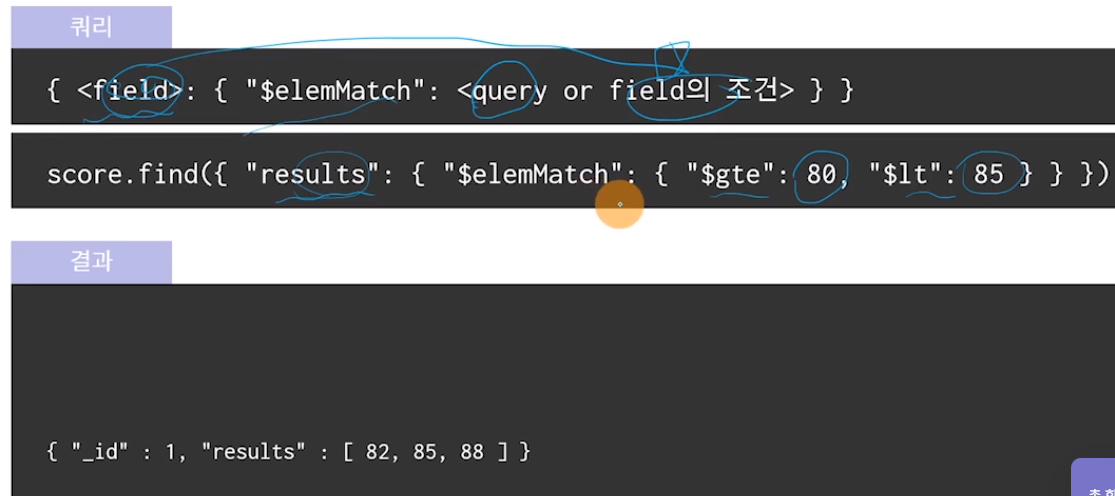

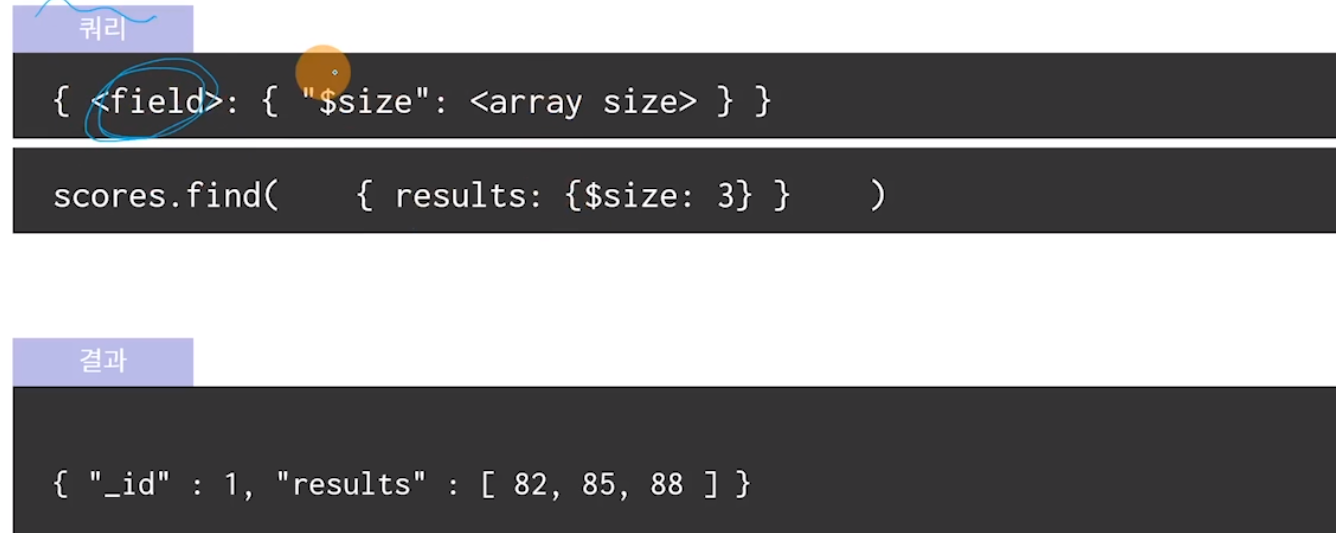
◆ 고급 활용 기능
세 가지 집계 방법론과 효율성
Find 명령으로 할 수 없는 것
지금까지 배운 Find 명령어로는 집계와 관련된 내용을 수행하지 못함.
ex. 강의 수강평 점수 평균 몇 점이고, 점수별로 얼마나 분포했는지 알아내는 것
도큐먼트를 집계하는 방법은 크게 세 가지가 있음.
- 데이터베이스 정보를 불러와 애플리케이션 단계에서 집계하는 방법 (애플리케이션 내부)
- MongoDB 맵-리듀스 기능을 이용하는 방법 (JS 엔진)
- MongoDB의 집계 파이프라인 기능을 이용하는 방법 (MongoDB 내부)
집계 명령의 특징
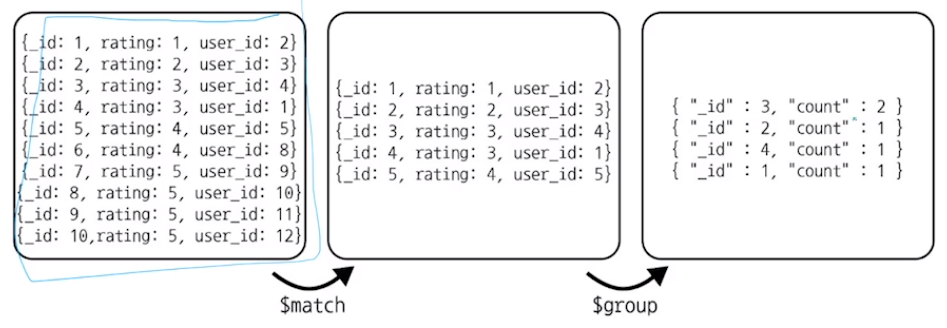
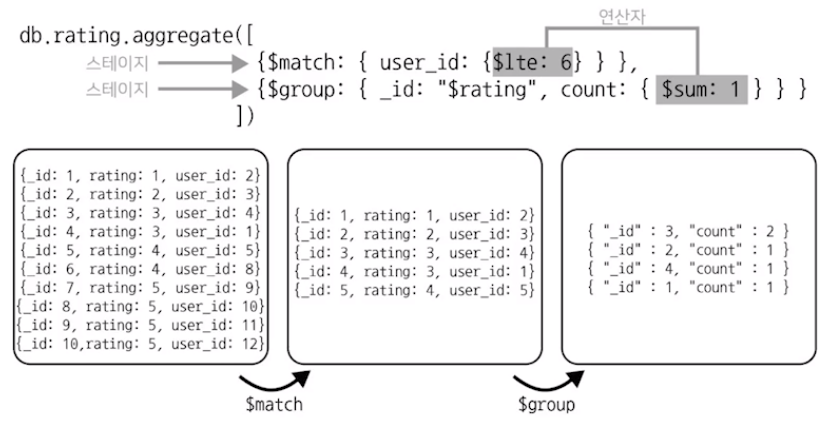
원본 데이터보다 결과 데이터의 양이 더 적다
집계 연산을 데이터 초기 단계에서 할수록 유리하다
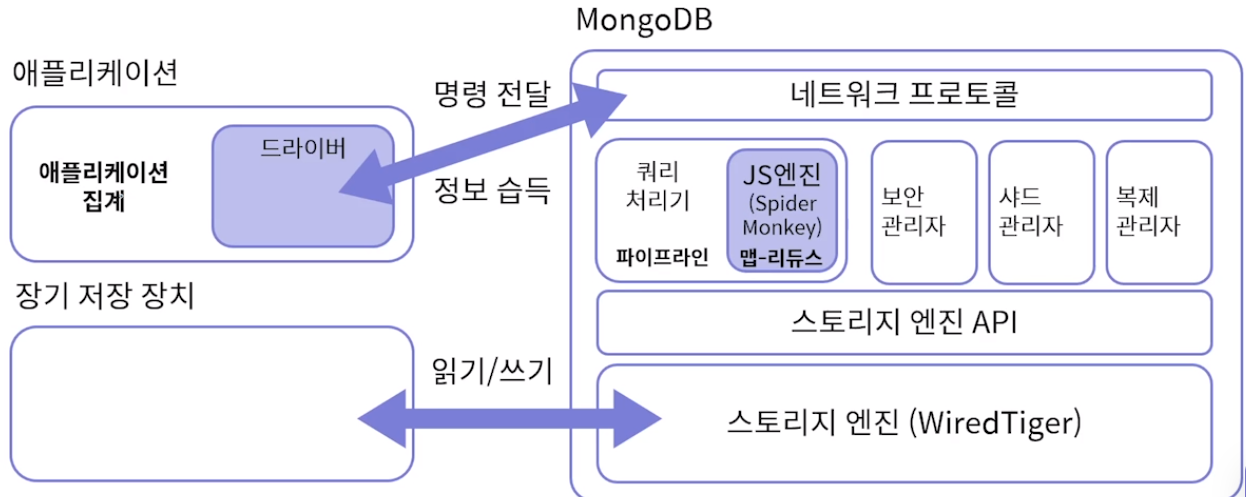
MongoDB와 웹 클라이언트의 통신 구조
- 처리 위치 : 애플리케이션 내부, JS 엔진, MongoDB 내부
- 처리 속도 : 애플리케이션 < 맵-리듀스 < 집계 파이프라인 (C언어, JS와 교환 X)
- 장기 저장장치와 가까울수록 속도가 빠름.
- JS와 정보 교환 안 할수록 효율적임. - 자유도 (원하는대로 데이터 가공) : 애플리케이션 > 맵-리듀스 > 집계 파이프라인
- 집계 파이프라인 : 미리 정해진 집계 스테이지대로 연산해야함.
- 맵-리듀스 : 정해진 루틴에 맞는 함수를 작성해서 집계 연산 가능
- 애플리케이션 : 원하는 코드 작성하여 집계처리 가능
맵-리듀스 소개

- 맵핑함수 : 관련된 정보끼리 그룹화
- 리듀스 함수 : 그룹 내 정보들을 집계 연산 (ex. 평균, 길이, 합산 ...)
맵-리듀스 함수의 데이터 처리 과정

집계 파이프라인 소개
파이프라인 : 한 데이터 처리 단계의 출력이 다음 단계의 입력으로 연결된 구조
인덱스 개요
제목을 기준으로 색인
- 일반적인 경우 기사의 분류별로 찾는일이 더 많았음.

분류를 기준으로 한 색인
- 분류만으로 기사 찾기 너무 불편함.
- 매번 기사가 추가될 때마다 색인을 수정해야 함.

분류-제목을 기준으로 한 색인
- 분류만으로 찾을 때도 쓸 수 있지만 가나다순으로 찾을 수 없음.

제목-분류 기준으로 한 색인
- 순서가 바뀌니 분류를 기준으로 찾기 어려움.

인덱스의 기능
- 앞선 예시의 색인과 거의 비슷한 기능을 수행함.
- 검색과 순서의 정렬을 효율적으로 만들어줌.

- 단순 인덱스 : 하나의 필드를 기준으로 생성한 인덱스
- 복합 인덱스 : 다수의 필드를 기준으로 생성한 인덱스
인덱스의 특징
- 쿼리를 수행할 때 인덱스가 없다면 모든 도큐먼트를 일일이 조회해야 한다.
→ 인덱스는 쿼리 작업을 매우 효율적으로 만든다. - 인덱스를 만들면 도큐먼트 생성 수정 시 인덱스를 업데이트해야 하기 때문에 속도 저하가 있음.
그러나 읽기 성능 향상이 훨씬 커서 인덱스를 생성하는 것이 권장됨.
(예외. 도큐먼트가 몇 시간마다 계속 생성됨 등) - 하나의 필드만 조회할 때는 단순 인덱스로 충분, 다수의 필드를 대상으로 조회할 때는 복합 인덱스가 유용함.
- a-b 복합 인덱스는 a 단순 인덱스와 같은 기능을 하므로 대체할 수 있음.
복제 세트 이해하기
복제 세트 : 같은 정보를 공유하는 Data Set
복제 세트를 사용하는 이유
- 높은 가용성(항상 사용할 수 있는 상태)을 위해서 - 선거를 통해 복구
- 정보의 안전한 보호를 위해
- Read 속도를 빠르게 하기 위해서 - 부차적인 기능, 선택사항
복제 세트의 구성원

복제 세트는 프라이머리, 세컨더리, 아비터 구성원으로 이루어져 있음.
Heartbeart로 서로의 상태를 확인한다.
복제 세트의 선거
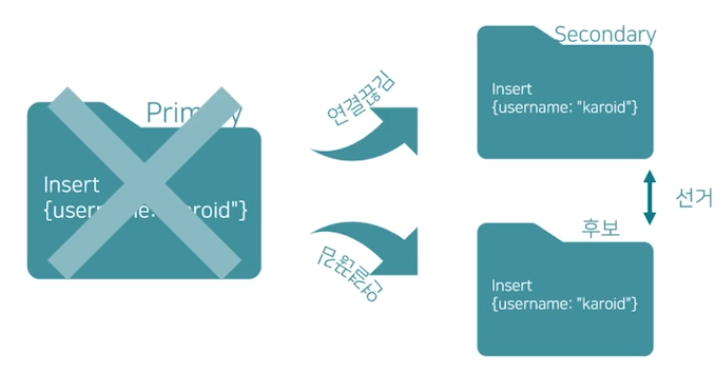
- 프라이머리가 무슨 이유에서든지 죽게 되면, 복제 세트 구성원 중 과반수의 세컨더리가 이를 감지하여 선거를 개최하기로 결정한다.
- 세컨더리와 아비터는 새로운 프라이머리를 뽑는 투표를 하게 된다.
- 우선순위가 높은 순서대로 세컨더리는 프라이머리 후보가 되고, 과반수의 찬성표를 받은 세컨더리는 프라이머리가 된다.
- 별 문제가 없으면 투표권자들은 찬성표를 던지지만, 다음과 같은 경우에는 반대표를 던진다.
ex. primary가 아직 제대로 작동, 후보 너보다 내가 더 최신 데이터를 전달 받음 등등
복제 세트의 또 하나의 장점
- 세컨더리를 활용해 읽기 기능을 확장할 수 있다.
- Secondary는 Primary와 어느 정도 비슷한 성능을 유지함.
- 단점 : 읽기에 지연이 생길 수 있음.

Read-Concern과 Write-Concern
Read-Concern과 Write-Concern이 필요한 이유
복제 세트에서 구성원의 정보가 동기화되는 데에는 필연적으로 시간이 필요
- Read-Concern : 어느 정도 동기화 수준을 기준으로 정보를 읽어올지 설정
- Write-Concern: 어느 정도 동기화 수준을 기준으로 쓰기 작업을 마무리할지 설정
설정 방법
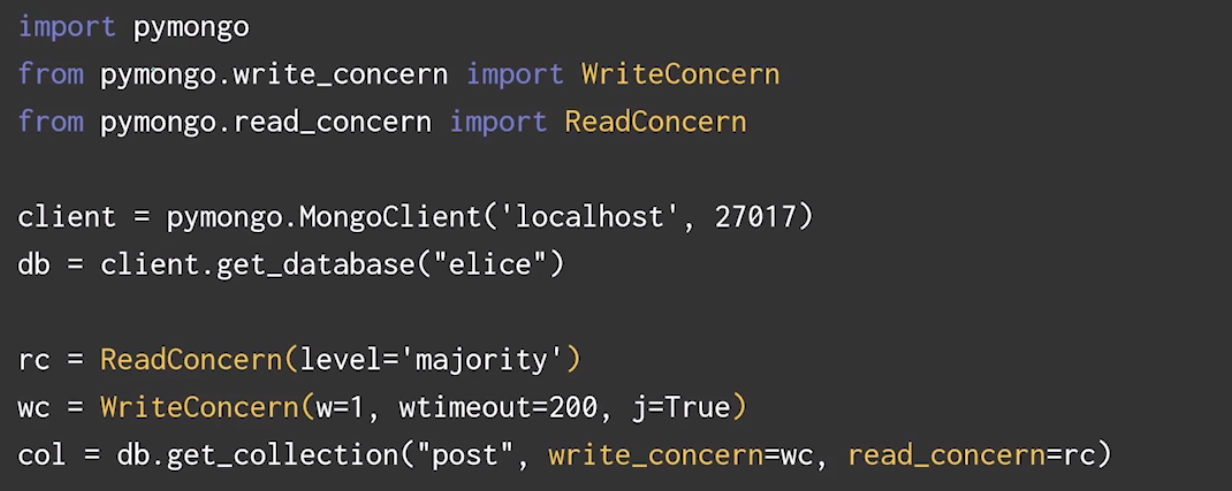
Read-Concern 설정
ReadConcern(level='majority')- local : 연결된 인스턴스에서만 정보를 불러온다
- majority : 복제 세트 대다수에 저장된 정보를 불러온다
- linearizable : 시간 제한 내에 복제 세트 구성원의 정보를 확인해서 대다수에 저장된 정보로 불러온다
MongoDB의 쓰기작업과 저널링
- 저널링 = 임시 저장 기술

Wrire-Concern과 저널링
WriteConcern(w=1, wtimeout=200, j=True)
Write-concern의 W옵션

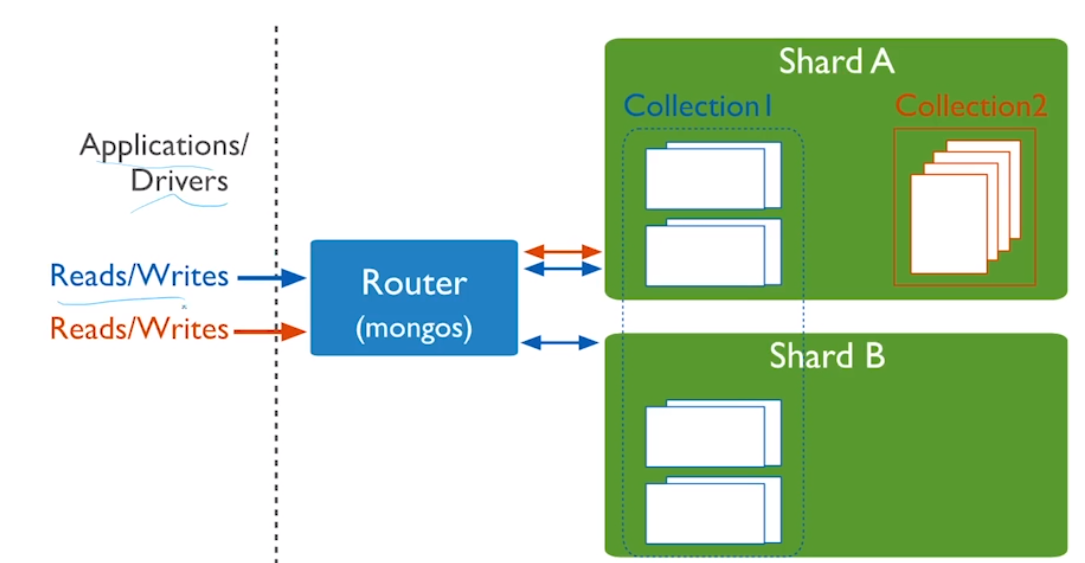
샤드 클러스터 이해하기
샤드 클러스터의 필요성
- 컴퓨터의 모든 장비는 고성능이 될수록 가성비가 안 좋아짐.
- 성능 2개 좋은 서버를 쓰는 것보다 2개의 서버를 쓰는 게 경제적이다.
샤드 클러스터의 구성

샤드 클러스터 작성 방식
- 샤드에 정보가 골고루 분산되어서 연산이 골고루 이루어져야 한다
샤딩의 기준
- 샤딩은 특정 필드 값을 기준으로 정보를 분산시킨다
- 3가지 기준으로 도큐먼트를 분산시킬 수 있음.

범위 샤딩
- 범위에 따라 분산하기 때문에 범위 조회 시 유리하다
- 하지만 특정 범위에 토큐먼트가 쏠리면 해당 샤드만 계속 바빠질 수 있다

해시 샤딩
- 장점: 두루두루 저장되어 한쪽에 몰릴 가능성이 낮다
- 단점: 범위를 찾는 쿼리를 수행할 때마다 다수의 클러스터에서 찾아야 한다

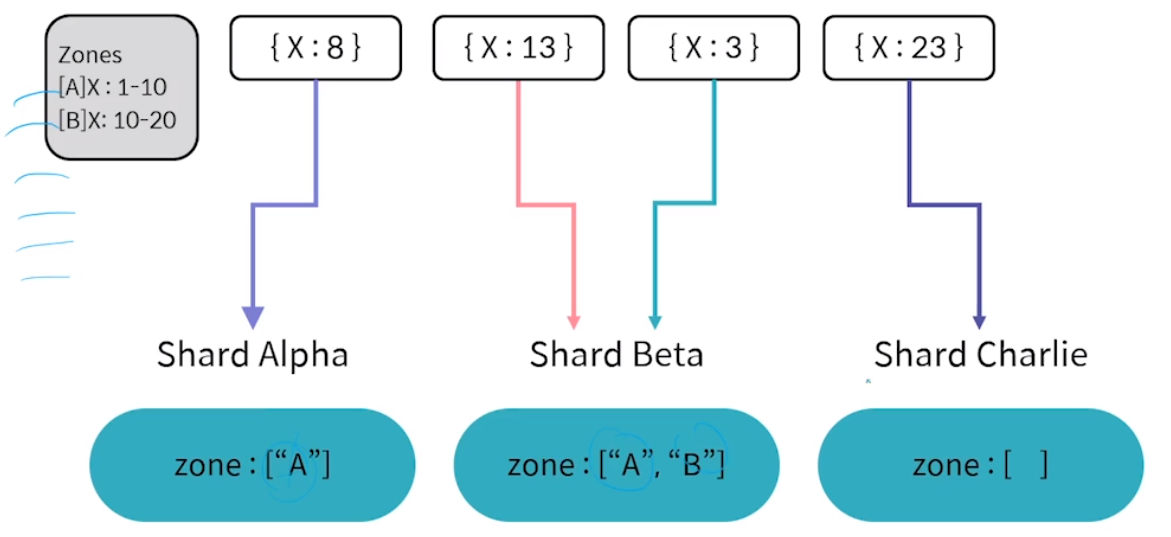
구역 샤딩
- 개발자가 존을 정해서 분배하는 방식
- 손이 많이 가지만 최적화된 샤드 구성을 만들 수 있다
'교육 > 엘리스 SW 트랙' 카테고리의 다른 글
| [엘리스sw] 프로젝트로 배우는 데이터베이스 (0) | 2024.05.03 |
|---|---|
| [엘리스sw] SQL로 데이터 다루기 Ⅰ (0) | 2024.04.29 |
| [엘리스sw] 13주차 3일 - styled-component (0) | 2024.03.26 |
| [엘리스sw] 13주차 1일 - SSR, 배포 (0) | 2024.03.26 |
| [엘리스sw] 12주차 5일 - React 테스팅 (0) | 2024.03.20 |



