
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 항해99
- node.js
- 방송대
- 코딩테스트준비
- 개발자취업
- 코딩테스트
- Git
- 오픈소스기반데이터분석
- 파이썬
- 코드잇
- mongoDB
- 유노코딩
- 꿀단집
- 프로그래머스
- TiL
- 엘리스sw트랙
- 99클럽
- 데이터베이스시스템
- nestjs
- 데이터분석
- 중간이들
- Azure
- CSS
- 클라우드컴퓨팅
- HTML
- 파이썬프로그래밍기초
- aws
- JavaScript
- Python
- 방송대컴퓨터과학과
- Today
- Total
배꼽파, 오늘도 배꼽 대신 데이터를 판다
실전 웹스크래핑: 기업 과제에서 Python BeautifulSoup으로 클래스 데이터 수집한 방법 본문

오늘은 실제 기업 과제를 진행하면서 홈페이지 데이터를 스크래핑했던 경험을 정리해보려고 한다.
과제 자체가 “크롤링”이 주제는 아니었지만, 과제를 수행하려면 회사 홈페이지에 있는 데이터를 수집해야 했다.
그래서 필요한 범위 안에서 스크래핑을 진행했다.
이번 작업에서는 Selenium 같은 브라우저 자동화 도구 대신 requests + BeautifulSoup 조합을 사용했다.
이유는 간단했다. 사이트를 확인해보니 자바스크립트 렌더링이나 복잡한 사용자 인터랙션 없이도 필요한 정보가 HTML에 그대로 들어 있었기 때문이다.
즉, 굳이 무거운 자동화 브라우저를 띄울 필요가 없었다.
1. 먼저 홈페이지부터 살펴보기
김용훈 그로스 연구소 그로스해킹 및 마케팅 컨설팅
그로스해킹, 그로스 마케팅을 통한 스타트업 비즈니스 컨설팅과 성장을 도와드립니다
leviyonghun.com
실전에서 스크래핑을 할 때는 코드를 바로 짜기보다, 사이트 구조를 먼저 확인하는 과정이 중요하다.
나는 아래 순서대로 확인했다.
1-1. robots.txt 확인
가장 먼저 robots.txt를 확인했다. 브라우저 메인 페이지 URL 뒤에 'robots.txt'를 입력한다.

User-agent: *
Disallow: /admin
Disallow: /api
Allow: /
User-agent: bingbot
Crawl-delay: 10
이 내용을 보면 다음처럼 해석할 수 있다.
- 모든 크롤러는 /admin, /api 경로를 제외하고 접근 가능
- bingbot은 요청 간 10초 딜레이 권장
즉, 적어도 robots.txt 기준으로는 공개 영역에 대한 접근 제한이 강한 편은 아니었다.
다만 여기서 주의할 점은, robots.txt가 곧 “무조건 크롤링해도 된다”는 뜻은 아니라는 것이다.
실무에서는 robots.txt뿐 아니라 서비스 이용약관, 요청 빈도, 서버 부하 가능성까지 함께 고려하는 게 안전하다고 한다.
1-2. 메인 페이지보다 “클래스” 탭이 더 적합했다
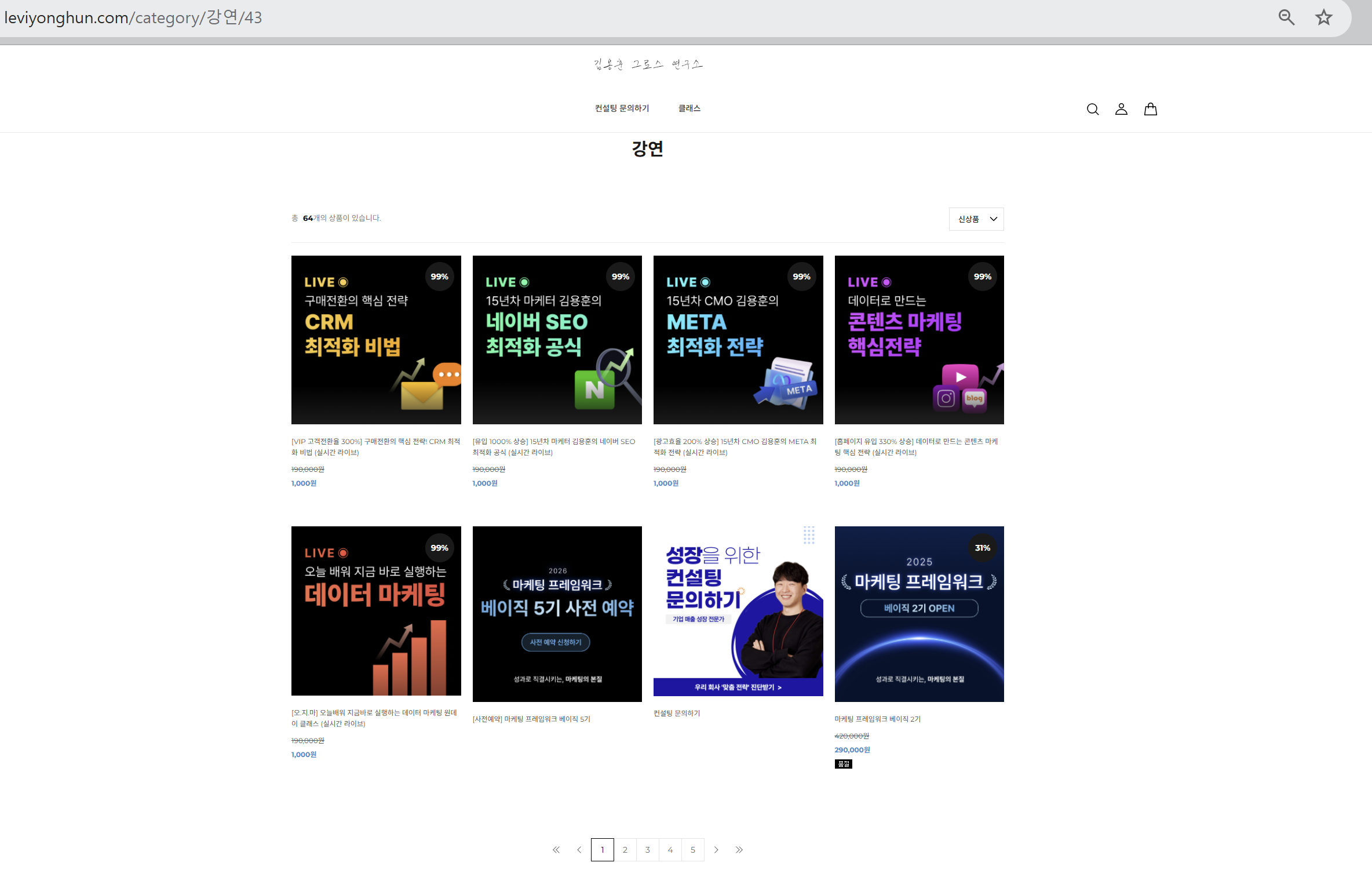
메인 사이트에도 클래스 정보가 일부 보였지만, 다른 정보들이 섞여 있어서 구조가 다소 복잡할 수 있다.
반면 ‘클래스’ 전용 탭은 동일한 형태의 상품 카드가 반복되는 구조라서, 스크래핑하기 훨씬 수월할 것 같았다.
실제로 들어가 보니 클래스는 총 64개였고, 내가 필요한 정보는 다음 3가지였다.
- 클래스명
- 가격
- 세부정보(간단 소개글)
이미지도 가져올 수는 있어 보였지만, 이번 과제 목적상 꼭 필요하지 않았다.
게다가 이미지 데이터는 다루는 비용이 크기 때문에, 실무에서도 정말 필요한 경우가 아니면 제외하는 편이 효율적이다.
2. URL 구조 확인: 이 사이트는 페이지네이션이 매우 단순했다
스크래핑하기 쉬운 사이트의 대표적인 특징 중 하나가 URL 규칙이 명확한 것이다.
이 사이트의 클래스 목록 URL은 아래와 같았다.
https://leviyonghun.com/category/%EA%B0%95%EC%97%B0/43?page=8
기본 URL은 다음과 같고,
https://leviyonghun.com/category/%EA%B0%95%EC%97%B0/43
여기에 ?page=페이지번호 형태로 쿼리 파라미터만 붙이면 됐다.
https://leviyonghun.com/category/%EA%B0%95%EC%97%B0/43?page=1
https://leviyonghun.com/category/%EA%B0%95%EC%97%B0/43?page=2
...
https://leviyonghun.com/category/%EA%B0%95%EC%97%B0/43?page=8
즉,
- 한 페이지당 최대 8개
- 총 8페이지
- page=1부터 page=8까지 반복 요청
이 구조라면 반복문으로 페이지 번호만 바꿔가며 요청하면 된다.
이런 경우는 Selenium 없이도 requests로 충분하다.
3. 어떤 정보가 실제로 들어 있는지 HTML 구조 확인하기
URL 구조를 확인했다면, 다음은 HTML 구조 분석이다.
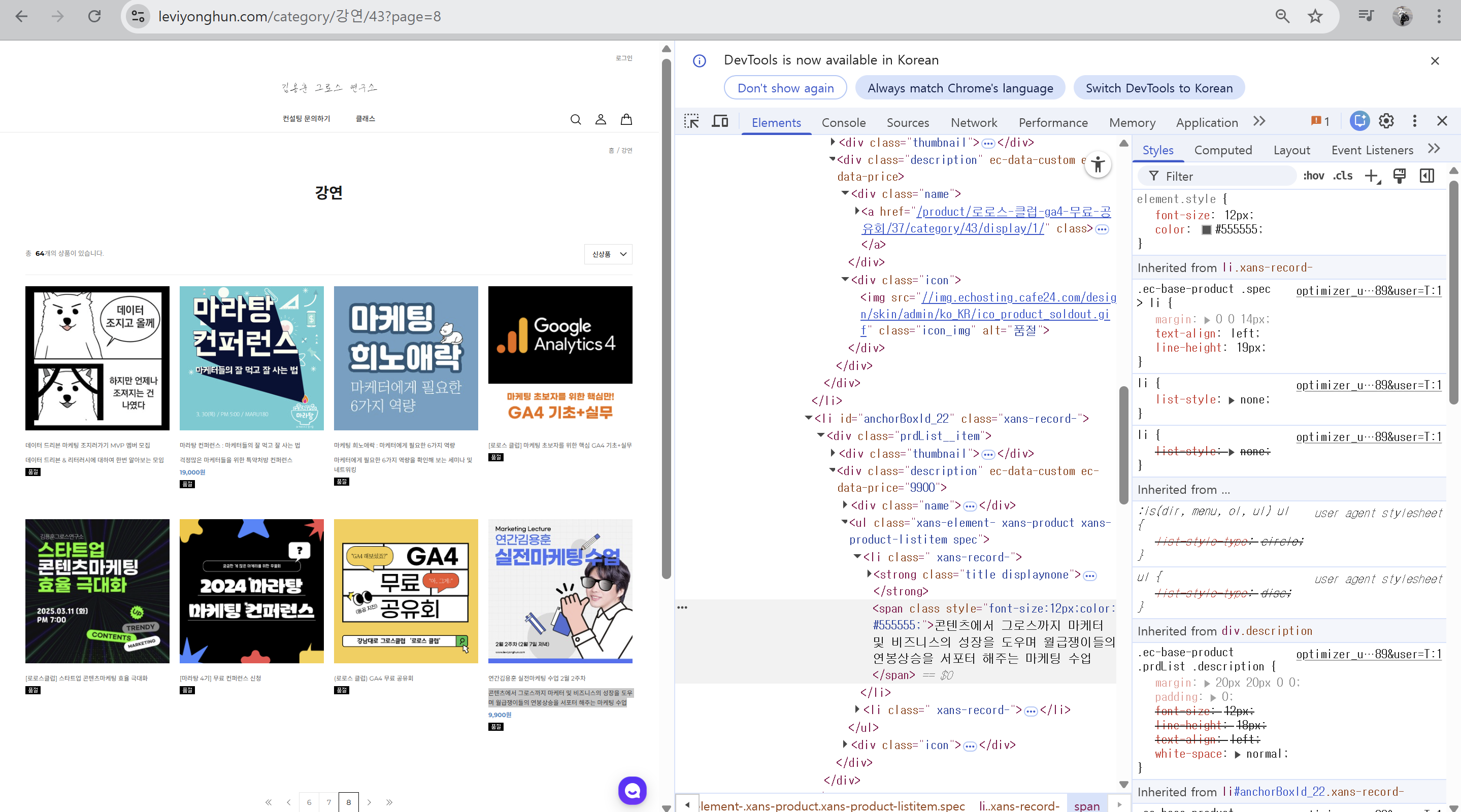
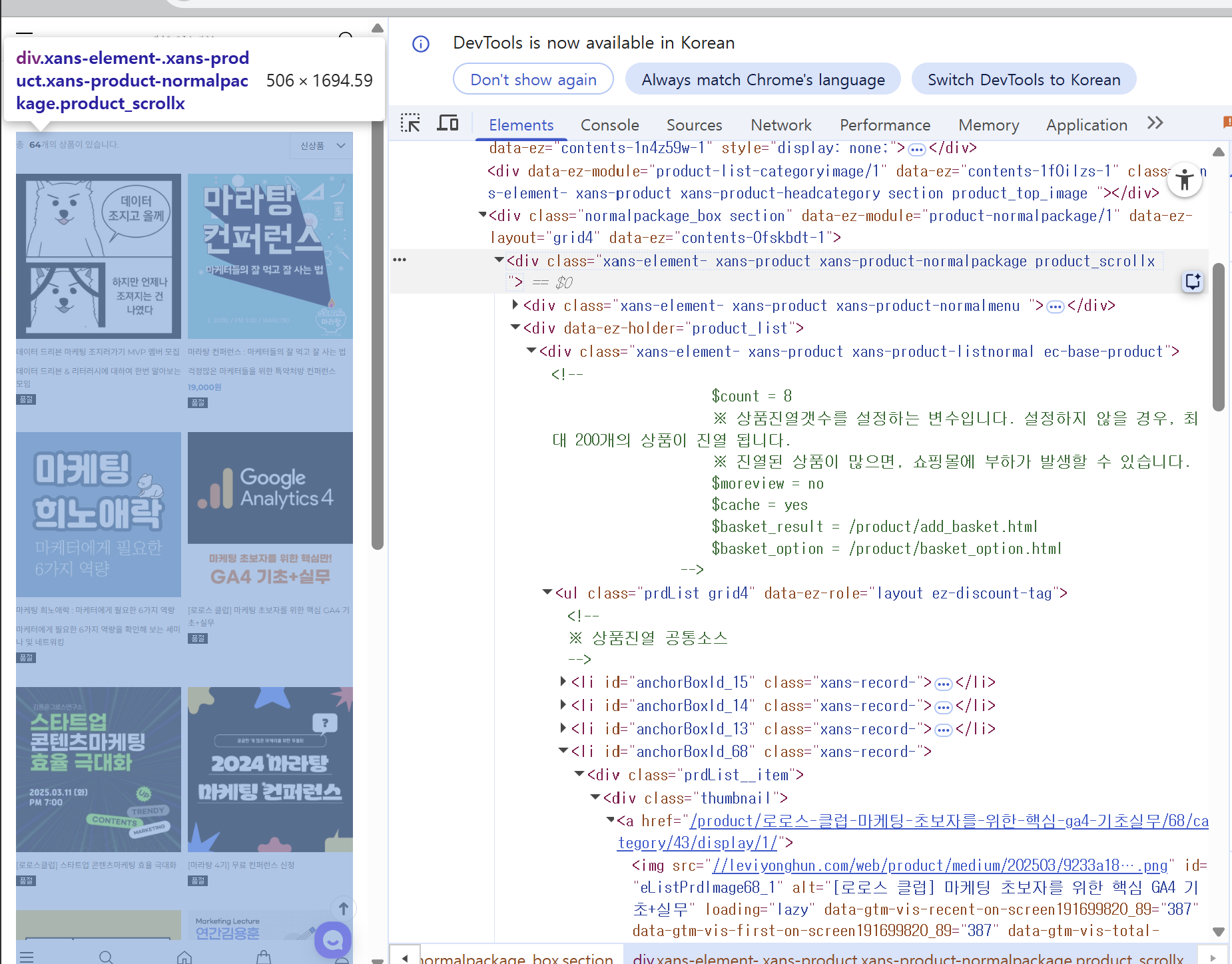
크롬 개발자도구에서
Ctrl + Shift + C 또는 좌측 상단의 요소 선택 아이콘을 누르면
화면에서 원하는 영역을 직접 찍어서 HTML 구조를 확인할 수 있다.
확인해보니 각 클래스는 다음과 같은 구조를 가지고 있었다.
<li id="anchorBoxId_47" class="xans-record-">
</li>
즉, 상품 하나가 li 태그 하나에 대응되고 있었고,
상품 단위 선택은 아래처럼 잡을 수 있었다.
- li[id^='anchorBoxId_']
이 안쪽 구조를 보면 대략 이렇게 되어 있었다.
- div.prdList__item
- div.thumbnail
- div.description
그리고 description 내부에는
- 상품명 영역
- 상세 정보 영역
- 가격 영역
이 들어 있었다.
예를 들어 상세 정보는 이런 형태였다.

이 구조를 보고 내가 정리한 기준은 다음과 같았다.
- li id="anchorBoxId_*" 단위로 상품 1개씩 접근
- 상품명 라벨 뒤 span = 실제 상품명
- 상품요약정보 라벨 뒤 span = 세부정보
- 판매가 라벨 뒤 span 중 원이 들어간 값 = 가격
4. 특이사항: 세부설명과 가격이 없는 클래스도 있었다
구조를 보다 보니 한 가지 특이점이 있었다.
처음에는 모든 클래스에
썸네일, 클래스명, 설명, 가격이 다 있을 줄 알았는데,
실제로는 세부설명이 없는 클래스도 있었고, 가격이 없는 클래스도 있었다.
즉, HTML 구조는 비슷하지만 조금씩 달랐다.
이럴 때는 억지로 값을 맞추려고 하기보다,
있으면 수집하고 없으면 결측값으로 두는 방식이 훨씬 안전하다.
이번 작업에서는 결측값을 그냥 공백 처리했다.
어차피 내가 보기만 하는 용도라서 그냥 내 기준에서 처리하면 된다!
5. 본격적인 크롤링 코드 작성 흐름
구조 분석이 끝났다면 이제 코드를 짤 차례다.
내가 잡은 흐름은 아래와 같았다.
5-1. requests로 페이지 요청 보내기
import requests
base_url = "https://leviyonghun.com/category/%EA%B0%95%EC%97%B0/43"
for page_nubmer in range(1, 9):
url = f"{base_url}?page={page_number}"
response = requests.get(url)
# 확인용
print(f"page {page_number}: {url}")
print(response.status_code)
params={"page": page_number}로 더 깔끔하게 작성할 수 있다.
import requests
url = "https://leviyonghun.com/category/%EA%B0%95%EC%97%B0/43"
for page_number in range(1, 9):
params = {"page": page_number}
response = requests.get(url, params=params)
print(response.url) # 확인용
그리고 한 줄로 줄이면 이렇게도 가능하다.
for page_number in range(1, 9):
response = requests.get(url, params={"page": page_number})
5-2. 필요한 변수 지정
수집 대상은 아래 3개였다.
- title : 클래스명
- price : 가격
- description : 세부정보
상품 하나를 순회할 때마다 이 변수들을 초기화해두고,
해당 값이 있으면 채우고 없으면 그대로 두는 방식으로 처리했다.
title = None
description = None
price = None
5-3. 선택자는 안정적인 구조 위주로 잡기
선택자를 잡을 때 너무 깊거나 복잡한 구조에 의존하면 쉽게 깨진다.
그래서 나는 고정된 HTML 구조 + 비교적 안정적인 선택자 위주로 접근했다.
기본 원칙은 아래와 같다.
- id, class, data-* 속성 기반 CSS selector 우선
- 상대 XPath는 필요할 때만
- 절대 XPath는 가급적 피하기
- 구조 분석할 때만 outerHTML 확인
정리하면,
- 코드 작성용 → CSS selector / XPath
- 구조 분석용 → outerHTML
이번 사이트에서는 특히 아래 구조가 핵심 기준점이었다.
<div class="function" id="Product_ListMenu">
<ul class="prdList grid4">
상품 리스트 전체가 이 블록 아래에 있었기 때문에,
여기서부터 하위 요소를 추적하면 비교적 안정적으로 접근할 수 있었다.
이제 아래부터 머리가 좀 아프다.
5-4. 제목 찾는 부분

우선 제목이 있는 부분은 아래와 같다.
<div class="name">
<a ...>
<span class="title displaynone">상품명 :</span>
<span>연간김용훈 실전마케팅 수업 2월 2주차</span>
</a>
</div>
여기서 a > span 이니까 a 바로 아래 있는 span 2개를 리스트로 가져와야 한다.
[
<span class="title displaynone">상품명 :</span>,
<span>연간김용훈 실전마케팅 수업 2월 2주차</span>
]
그럼 이 리스트에서 첫 번째 말고, 두 번째 span 태그에 있는 글자를 가져와야 할 것이다.
이건
- 0번째 = 라벨 "상품명 :"
- 1번째 = 실제 제목
이라서 name_spans[1]을 title로 넣는 것이다.
아래와 같은 코드를 작성한다.
if len(name_spans) >= 2:
title = name_spans[1].get_text(strip=True)
5-5. 상품요약정보 / 판매가 찾는 부분
이 부분은 더 골때린다. 자세히 보면 ul > li > strong, span 이렇게 구성되어 있다.
<li>
<strong class="title displaynone"><span>상품요약정보</span> :</strong>
<span>콘텐츠에서 그로스까지 ...</span>
</li>
<li>
<strong class="title displaynone"><span>판매가</span> :</strong>
<span>9,900원</span>
</li>
즉 li 하나하나가
- 상품요약정보 줄일 수도 있고
- 판매가 줄일 수도 있다.
5-6. 지금 li가 무슨 항목인지 확인
지금 li가 상세 정보나 가격 중 무슨 항목인지 확인한다.
strong = li.select_one("strong")
label = strong.get_text(" ", strip=True) if strong else ""strong 태그일 때 태그 안 글자를 label 변수에 넣어준다.
예를 들어 다음과 같은게 있다면,
<strong class="어쩌구"><span>상품요약정보</span> :</strong>그럼 여기서 label은 '상품요약정보 :'가 될 것이다.
이런식으로 안에 들어 있는게, 상품요약정보인지, 판매가인지 구분하면 된다.
5-7. 값 가져오는 부분
<li>
<strong><span>상품요약정보</span> :</strong>
<span>콘텐츠에서 그로스까지 ...</span>
</li>이렇게 생겼으면 strong 태그로 감싸진 거 제외하고, 그 아래 span만 있는 것만 가져와야 한다.
value_spans = li.find_all("span", recursive=False)
value = value_spans[0].get_text(strip=True) if value_spans else Noneli 태그 안에 바로 span이 나오는 태그만 가져와서, 해당 텍스트를 value로 넣어준다.
5-8. 최종 분기
if "상품요약정보" in label:
description = value
elif "판매가" in label and value and "원" in value:
price = value
- label에 "상품요약정보"가 들어 있으면 → 그 값은 description
- label에 "판매가"가 들어 있으면 → 그 값은 price
여기까지 코드 흐름은 다음과 같다.
for li in product.select(".description ul.spec > li"):
strong = li.select_one("strong")
label = strong.get_text(" ", strip=True) if strong else ""
value_spans = li.find_all("span", reculsive=False)
value = value_spans[0].get_text(strip=True) if value_spans else None
if "상품요약정보" in label:
description = value
elif "판매가" in label and value and "원" in value:
price = value
흐름은 아래와 같다.
상품 li 하나씩 꺼냄
└ 제목 영역에서 실제 제목 span 찾음
└ spec 안의 li들을 돌면서
└ 라벨이 "상품요약정보"면 description 저장
└ 라벨이 "판매가"면 price 저장
코드는 아래와 같다.
결측값은 별도로 복잡하게 처리하지 않았다.
import requests
from bs4 import BeautifulSoup
base_url = "https://leviyonghun.com/category/%EA%B0%95%EC%97%B0/43"
headers = {
"User-Agent": "Mozilla/5.0"
}
all_products = []
for page_number in range(1, 9):
params = {"page": page_number}
response = requests.get(base_url, params=params, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
for product in soup.select("ul.prdList > li[id^='anchorBoxId_']"):
title = None
description = None
price = None
name_spans = product.select(".description .name a > span")
if len(name_spans) >= 2:
title = name_spans[1].get_text(strip=True)
for li in product.select(".description ul.spec > li"):
strong = li.select_one("strong")
label = strong.get_text(" ", strip=True) if strong else ""
value_spans = li.find_all("span", recursive=False)
value = value_spans[0].get_text(strip=True) if value_spans else None
if "상품요약정보" in label:
description = value
elif "판매가" in label and value and "원" in value:
price = value
all_products.append({
"page": page_number,
"title": title,
"price": price,
"description": description
})
for item in all_products:
print(item)
출력하면 all_products 리스트 안 딕셔너리 형태로 데이터를 확인 가능하다.

6. 데이터 DataFrame으로 변환 후 xlsx 파일로 저장
마지막으로 수집한 데이터를 DataFrame으로 변환 후 xlsx 파일로 저장했다.
import pandas as pd
# 리스트 -> DataFrame 변환
df = pd.DataFrame(all_products)
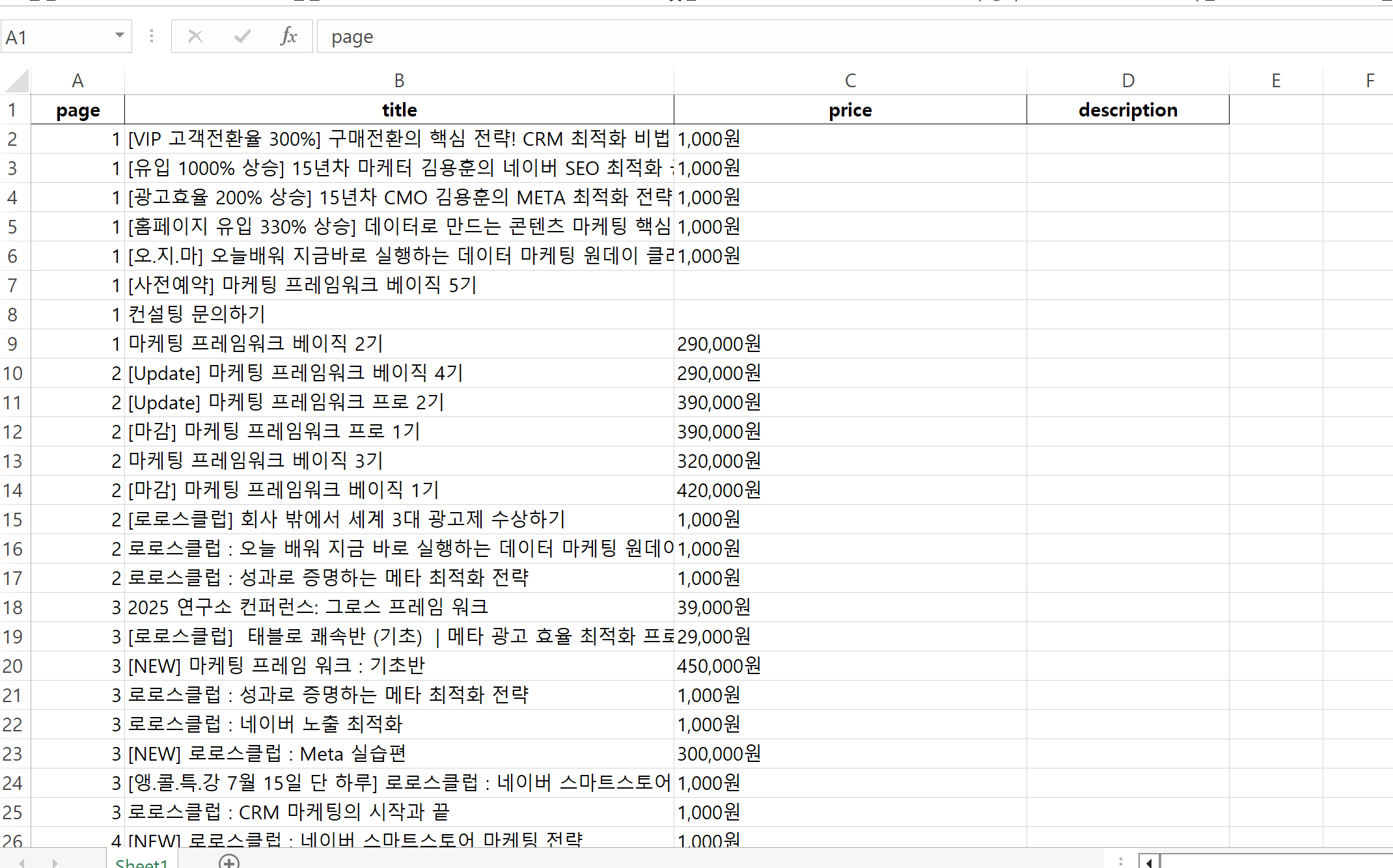
엑셀 파일을 열어보면 원하는대로 데이터가 정리된 걸 볼 수 있다.

7. 마무리
이번 스크래핑 작업은 기술적으로 아주 어려운 편은 아니었다.
네이버나 구글처럼 구조가 복잡해서 F12를 눌러보자마자 손 놓고 싶은 사이트에 비하면, 매우 단순한 형태였기 때문에 접근하기 수월했다.
전체 작업 순서는 아래와 같았다.
- robots.txt와 사이트 구조를 먼저 살펴본다.
- URL 규칙을 확인한다.
- HTML 구조를 분석하고, 그 안에 필요한 데이터가 실제로 들어 있는지 확인한다.
- 결측값이 있는지 보고, 어떻게 처리할지 결정한다.
- 선택자는 최대한 변동 가능성이 적은 것으로 잡는다.
- 코드를 작성한 뒤, 데이터를 원하는 형태로 가공하여 추출한다.
결국 스크래핑은 무작정 코드부터 짜는 작업이 아니라,
사이트 구조를 먼저 읽고 필요한 데이터가 어디에 어떻게 들어 있는지 파악하는 과정이 더 중요하다고 느꼈다.
예전에는 웹스크래핑이 어렵고 복잡한 작업처럼 느껴졌지만,
요즘은 구조만 잘 파악하면 필요한 데이터 정도는 훨씬 수월하게 수집할 수 있는 환경이 된 것 같다.
코드 작성이 어려우면 AI의 도움을 받으면 된다.
이번 글이 실제로 스크래핑을 처음 해보려는 사람들에게 조금이나마 도움이 되었으면 한다.
'실전 기술 활용 > 데이터 수집' 카테고리의 다른 글
| TED 자막 복붙 안 될 때: 브라우저 DevTools로 스크립트 추출하는 법 (0) | 2026.04.12 |
|---|
