| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 데이터베이스시스템
- 중간이들
- 항해99
- 클라우드컴퓨팅
- 프로그래머스
- aws
- Azure
- Git
- 99클럽
- node.js
- mongoDB
- 파이썬
- JavaScript
- Python
- 방송대
- CSS
- 꿀단집
- 유노코딩
- 엘리스sw트랙
- TiL
- redis
- 코드잇
- 개발자취업
- 오픈소스기반데이터분석
- 코딩테스트
- 파이썬프로그래밍기초
- nestjs
- 방송대컴퓨터과학과
- 코딩테스트준비
- HTML
- Today
- Total
배꼽파지 않도록 잘 개발해요
방송대 데이터베이스시스템 - 3강. 관계형 모델 본문

1. 관계형 모델
논리적 데이터 모델링 단계
- DBMS에서 사용하는 데이터 모델에 맞추어 데이터를 표현하는 과정
- 데이터 정의 언어로 기술된 개념 스키마 생성
관계형 모델(relational model)
- 1969년 에드가 F.코드에 의해 제안
- 릴레이션(relation)으로 데이터를 표현하는 모델
- 데이터 표현이 단순하고 직관적 구조화 모델
- 현재 대다수 상용 DBMS가 관계형 모델을 사용함(Oracle, DB2, PostgreSQL, MySQL, MSSQL 등)
릴레이션(relation)
- 관계형 모델에서 표와 유사하게 2차원 구조로 데이터를 표현하여 저장하는 것
릴레이션의 구성

릴레이션은 두 개의 메타데이터를 표현해서 하나의 값을 데이터화시키는 그 과정에 가장 최적화된 구조
ex. '02-3668-4650'은 컴퓨터과학과의 전화번호에 해당되는 컬럼값
→ 두 개의 메타데이터에 해당하는 값
| 컬럼(Column, 열) 필드(Field) 속성(Attribute) |
컬럼에 해당하는 값의 집합 ex. {학과이름, 단과대학, 주소, 전화번호, 졸업학점} |
| 레코드(Record) 행(Row) 투플(Tuple) |
각 컬럼의 순서에 맞게 나열된 값의 집합 ex. {컴퓨터과학과, 자연과학대학, http://cs.knou.ac.kr/, 02-3669-4650, 130} |
| 도메인(Domain, 영역) | 컬럼이 가질 수 있는 값의 범위 |
| 스키마(Schema) | 컬럼, 각 컬럼의 순서 및 도메인, 릴레이션의 이름 테이블에서 사용되는 컬럼과 컬럼이 지니는 데이터 타입을 정의한 것 (잘 변하지 않음) ex. 표 제목처럼 '학과이름, 단과대학, 주소, 전화번호, 졸업학점' 부분만 |
| 인스턴스(Instance) | 특정 시점에서의 릴레이션 스키마에 맞춰서 레코드가 들어간 상태 (시간에 따라 변함) 변수에 저장되어 있는 정숫값과 유사 |
| 차수(Degree) | 릴레이션에 존재하는 속성의 개수 |
| 카디널리티(Cardinality) | 릴레이션에 존재하는 레코드의 개수 |
릴레이션의 특징
| 레코드의 유일성 | 하나의 릴레이션에는 중복되는 레코드가 존재할 수 없음. 하나의 키 값으로 하나의 레코드를 유일하게 식별함. |
| 레코드의 무순서성 | 한 릴레이션에 포함된 레코드는 순서가 정해져 있지 않음. |
| 컬럼의 무순서성 | 한 릴레이션을 구성하는 컬럼 사이에는 순서가 없으며, 이름과 값의 쌍으로 구성됨. |
| 컬럼값의 원자성 | 컬럼은 여러 의미를 갖는 값으로 분해가 불가능하며 원자적(atomic)임. |
키(key)
- 릴레이션의 레코드를 유일하게 십결하는 역할을 하는 컬럼 또는 컬럼의 집합
키의 속성
| 유일성(uniqueness) | 키 컬럼의 값은 중복될 수 없고, 한 개의 키 값은 한 레코드에만 해당됨. |
| 최소성(irreducibility) | 키는 유일성을 유지하기 위한 최소의 컬럼으로만 구성됨. |
주 키 속성/주속성/비주속성
| 주 키 속성(Primary Key Attribute) | 테이블에서 각 행 또는 레코드를 고유하게 식별하는 데 사용되는 속성 주 키는 테이블에서 유일해야 하며, 각 행에는 고유한 주 키 값이 있어야 함. |
| 주속성(Primary Attribute) | 테이블의 주요한 속성, 테이블의 핵심 정보를 나타내는 속성 테이블의 기본적인 특징을 정의하는데 사용됨. |
| 비주속성(Non-Primary Attribute) | 주 키 속성이 아닌 테이블의 속성 추가 정보나 특성을 제공하지만, 행을 고유하게 식별하는데 사용되지 않음. |
ex. 학생 테이블
| 학번 (Student ID) | 이름 (Name) | 전공 (Major) | 학년 (Grade) |
| 주 키 속성 | 주속성 | 비주속성 | 비주속성 |
학번 : 각 학생은 고유한 학번을 가지고 있으며, 이를 통해 각 학생을 식별할 수 있음. → 주 키 속성
이름 : 테이블의 주요한 속성으로, 기본적인 특징을 정의하는데 사용됨. → 주속성
전공, 학년 : 레코드를 고유하게 식별하는데 사용되지 않음 → 비주속성
키의 종류
| 수퍼키(super key) | 레코드를 고유하게 구별할 수 있는 컬럼의 집합 → 유일성 만족 |
| 후보키(candidate key) | 수퍼키 중에서도 최소한의 컬럼으로 구성된 수퍼키 → 유일성, 최소성 만족 |
| 기본키(PK: primary key) | 여러 후보키 중 레코드를 구분하기 위해 지정한 후보키 중 하나 |
| 외래키(FK: foreign key) | 참조된 다른 릴레이션의 기본키 |

수퍼키 : 학과이름, {학과이름, 단과대학}, 주소, 전화번호, {전화번호, 졸업학점}
후보키 : 학과이름, 주소, 전화번호
- '단과대학'의 경우 중복된 단과대학 이름이 여러 개 있어서 겹치는 속성값이 있음.
기본키 : 힉과이름
키의 참조
목적 : 두 릴레이션에 포함된 레코드 간 연관성을 표현
외래키는 A 릴레이션의 속성으로 정의되며, 이 속성은 참조되는 B 릴레이션의 기본키와 동일한 값을 가져야 함.
일반적으로 외래키는 NULL 값을 가질 수 있지만, 이는 참조되는 B 릴레이션의 기본키가 NULL 값을 허용하는 경우에만 해당됨.
참조 무결성(Referential Integrity) 유지 : 외래키는 참조하는 테이블의 기본키 값과 일치해야 하며, 참조된 테이블의 기본키 값이 변경되거나 삭제되는 경우에도 데이터의 일관성을 보장함.

교수 릴레이션의 속성인 소속학과(FK)는 학과 릴레이션의 속성인 학과이름(PK)를 참조함.
관계형 모델의 제약조건
| 영역 제약 조건 (domain constraints) |
컬럼에 정의된 영역(domain)에 속한 값으로만 컬럼값이 결정, 원자적(atomic)이여야 함. ex. 전화번호에는 문자가 들어갈 수 없다, 학과에 컴퓨터과학과(O), 컴퓨터과학과/생활과학과(X) |
| 키 제약조건 (key constraints) |
키는 레코드를 고유하게 구별하는 값으로 구성 적어도 하나의 키가 모든 레코드를 고유하게 식별할 수 있어야 함 |
| 개체 무결성 제약조건 (entity integrity constraints) |
어떠한 기본키 값도 널(null)이 될 수 없음 |
| 참조 무결성 제약조건 (referential integrity constraints) |
외래키가 반드시 존재하는 레코드의 기본키만 참조 가능 |
널(NULL)의 개념
'없음' 또는 '0'이 아닌 미지의 값에 대한 표현
- 입력된 적이 없는 값
- 적용 불가능한 값
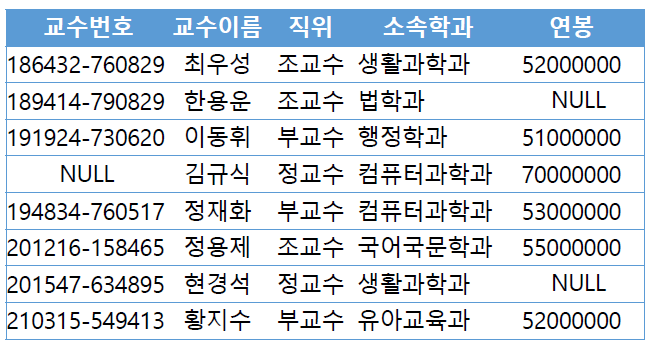
교수번호(PK)가 NULL인 김규식 교수의 경우, 동명이인이 있을 때 레코드를 특정지어 수정을 할 수 없어 무결성을 회복하기 힘들다.
→ 항상 기본키에 해당하는 값들은 어떤 새로운 레코드가 삽입될 때 무조건 값이 차있어야 함.
2. ERD의 변환
논리적 데이터 모델링
DBMS의 구현 모델에 맞춰 데이터를 표현하는 과정
데이터 정의 언어로 기술된 개념 스키마 생성
논리적 데이터 모델링의 필요
- 관계형 DBMS(RDBMS)의 구현 모델에 맞춰 데이터의 구조와 관계를 표현
- 작성된 ERD를 RDBMS가 수용 가능하는 구조로 변환
관계형 모델로 변환 방법
| 단계 1 | 개체 집합 | 개체 집합은 릴레이션으로 변환 |
| 단계 2 | 약한 개체 집합 | 강한 개체 집합의 키 속성을 약한 개체 집합의 릴레이션에 포함 |
| 단계 3 | 일대일 관계 | 두 릴레이션 중에서 한 릴레이션의 기본키를 다른 릴레이션에 외래키로 참조 |
| 단계 4 | 일대다 혹은 다대일 관계 | '일'쪽의 기본키를 '다'쪽 릴레이션에서 외래키로 참조 |
| 단계 5 | 다대다 관계 | 관계 릴레이션을 생성하고, 두 릴레이션의 기본키를 각각 참조하는 외래키를 복합키 형태의 컬럼으로 구성 |
| 단계 6 | 다중값 속성 | 릴레이션의 기본키를 참조하는 외래키와 다중값 속성으로 별도의 릴레이션으로 구성 |
| 단계 7 | 관계 집합의 속성 | 외래키가 위치한 릴레이션의 컬럼으로 삽 |
ER 다이어그램의 변환
| ER모델 | → | 관계형 모델 |
| 속성 (키 속성) | → | 컬럼 (기본키) |
| 개체집합 | → | 릴레이션 |
| 개체 | → | 레코드 |


일대다 관계 : 한 명의 교수는 여러 과목을 강의할 수 있고, 한 개의 과목은 한 명의 교수에 의해 강의되어야 함.
부분적 참가(실선) : 교수 중에서 과목을 강의하지 않는 교수가 있다.
전체적 참가(이중선) : 어떤 과목을 강의하는 교수가 반드시 존재한다.
교수 개체집합을 교수 릴레이션으로 만들어서 속성(교수번호, 교수이름, 직위, 연봉)을 컬럼으로 만든 후,
키 속성인 '교수이름'을 릴레이션의 기본키(PK)로 설정함.
과목 개체집합을 과목 릴레이션으로 만들어서 속성(과목코드, 과목명, 학점, 교수번호)을 컬럼으로 만든 후,
키 속성인 '과목코드'을 릴레이션의 기본키(PK)로 설정함.
강의 관계집합은 교수 릴레이션(일)의 기본키인 교수번호를 과목 릴레이션(다)에 외래키(FK)를 생성하는 것으로 나타냄.

다대다 관계를 가지는 경우, 어느 한 릴레이션이 외래키로 들어갈 수 없음.
별도의 릴레이션을 생성하여 두 개체의 기본키(학생번호, 과목코드)와 관계 집합의 추가 속성(신청시각)을 추가해줌.
기본키는 두 개체의 키를 합쳐서(학생번호, 과목코드) 만들고,
학생번호는 학생 릴레이션을 참조하는 외래키, 과목코드는 과목 릴레이션을 참조하는 외래키가 됨.

일대일 관계의 경우, 되도록 속성 개수가 적은 쪽에 외래키를 설정하는 게 좋음.
수강 릴레이션에 학생 릴레이션의 기본키인 학생번호를 외래키로 설정함.
약한 개체 집합인 계좌는 릴레이션으로 변환시 '계좌번호'(약한 개체 집합의 키 속성)와 '학생번호'(강한 개체 집합의 키 속성)를 합쳐서 기본키로 만들어짐.
3. 데이터 연산
관계 연산의 개념
관계형 모델을 기반으로 구성된 릴레이션을 사용하여 새로운 릴레이션을 생성하는 표현
사용자의 관점에서 필요한 데이터를 릴레이션에서 추출하는 방법을 제공하는 도구
· SQL : 질의에서 필요한 데이터와 데이터에 대한 조건만을 기술 (선언적 언어)
· 관계 대수 : 질의에 대한 처리 과정을 단계적으로 표현 (절차적 언어)
관계 대수(relational algebra)
- 관계 연산을 정의하는 방법
- 주어진 릴레이션에서 필요한 릴레이션을 만드는 연산자(∪, ∩, -, σ , π, x, ⋈, ÷ , 집계함수 등)로 구성
- 관계 대수 연산자는 새로운 임시 릴레이션을 생성
- 연산자를 중첩하여 연산 처리 절차를 표현
| 기본 연산자 |
||
| 단항연산자 | ||
| 셀렉트 (Select) | σ (Sigma) | 릴레이션에서 조건에 만족하는 레코드들을 선택 |
| 프로젝트 (Project) | π (Pi) | 입력된 릴레이션의 특정 컬럼만을 추출하여 새로운 릴레이션으로 재구성 |
| 리네임 (Rename) | ρ (Rho) | 관계 대수식에 새로운 이름을 부여 |
| 이항연산자 | ||
| 합집합 (Union) | ∪ (Union) | 두 릴레이션이 포함된 모든 레코드를 갖는 릴레이션을 결과로 반환 |
| 차집합 (Difference) | - (Minus) | 한 릴레이션에는 포함되지만 다른 릴레이션에는 포함되지 않는 레코드를 가지는 릴레이션을 결과로 반환 |
| 교집합 (Intersection) | ∩ (Intersection) | 양쪽 릴레이션에 동시에 포함되는 레코드의 집합을 생성 |
| 카디션 프로덕트 (Cartesian Product) | × (Cross) | 두 릴레이션 레코드 간 모든 조합을 취하여 결합한 레코드를 생산 (m+n개의 컬럼, axb개의 레코드) |
| 조인 (Join) | ⋈ (Join) | 두 릴레이션으로부터 서로 관련된 레코드만 결합하여 결과 집합에 포함 |
| 외부 연산자 | ||
| 자연조인 연산자 | ⋈ₙ | 카디션 프로덕트가 사용된 복잡한 관계 대수식을 간단하게 만들 때 사용 |
| 할당 연산자 | ← (Left arrow) | 관계 대수식의 결과를 임시적으로 릴레이션 변수에 저장 |
| 집계 함수 연산자 | 𝒢 (Caligraph G) | sum, avg, count, max, min |
| 외부조인 (왼쪽, 오른쪽, 완전) | ||
셀렉트 연산
주어진 릴레이션에서 조건을 만족하는 레코드를 갖는 릴레이션을 생성

조건 : a Θ b 또는 a Θ v
- a, b : 속성 이름
- Θ : 비교자 {=, ≠, <, >, ≤, ≥}
- v : 상수 값
- R : 릴레이션
조건의 결합 : ∧(and), ∨(or)
 |
 |
| 교수 릴레이션에서 소속학과가 컴퓨터과학과인 레코드만 추출 | 연봉이 5천만원 이상인(and) 교수 릴레이션에서 소속학과가 컴퓨터과학과인 레코드만 추출 |
프로젝트 연산
기술된 컬럼만 갖는 릴레이션으로 재구성

<컬럼리스트> : A₁, A₂, ..., Aₙ와 같이 R 에 존재하는 컬럼을 콤마로 분리하여 기술

교수 릴레이션에서 '교수이름'과 '소속학과' 컬럼만 있는 릴레이션으로 재구성
관계 대수 연산식의 활용
Q. 직위가 '부교수'인 교수의 교수이름을 출력하라.
 |
 |
| 교수 릴레이션에서 직위가 부교수인 레코드만 추출함. | 이전에 추출된 레코드(직위=부교수) 중 교수이름 컬럼만 출력되는 릴레이션을 재구성함. |
집합 연산자
수학적 집합 이론에서의 이진 연산
- 합집합 : R ∪ S
- 교집합 : R ∩ S
- 차집합 : R - S
릴레이션은 집합 , 레코드는 집합에 포함된 원소
집합 연산자 사용 조건 (호환 가능한 릴레이션 간에만 사용)
- 릴레이션 R 과 S 의 차수(한 릴레이션에 포함된 컬럼의 개수)가 동일
- 모든 i 에 대해 R 의 i 번째 컬럼의 도메인과 S 의 i 번째 컬럼의 도메인이 반드시 동일
카티시언 프로덕트 연산
두 릴레이션에 포함된 레코드 간의 모든 조합을 생성하는 이항 연산자

R에는 m개의 컬럼과 a개의 레코드가, S에는 n개의 컬럼과 b개의 레코드가 있음.
R X S는 (m+n)개의 컬럼과 a x b개의 레코드가 존재함.
 |
 |
| 학과 릴레이션이 교수 릴레이션의 '소속학과' 컬럼에 들어가는데, 카티시언 프로덕트는 연관성 상관 없이 나올 수 있는 모든 경우를 나타냄. | |
조인 연산
두 릴레이션에서 조건을 만족하는 레코드를 결합한 레코드로 구성된 릴레이션을 생성함.
카티시언 프로덕트는 무작위로 모든 조합을 하는 반면, 조인 연산은 조건을 만족하는 레코드만 결합함.

우선 카티시언 프로덕트를 수행하고 나서 그 다음에 만들어진 쓸데없는 레코드 중 조건을 만족하는 레코드만 셀렉트함.
조인 연산은 카티시언 프로덕트(X)와 셀렉트 연산(σ)의 결합으로 내부적으로 처리됨.
Q. '컴퓨터과학과' 소속의 교수가 강의하는 과목의 과목명과 과목코드는?
| 1 |  |
과목과 교수 두 릴레이션을 카티시언 프로덕트함. 과목과 교수 릴레이션의 모든 조합이 이루어짐. |
| 2 |  |
이중 제대로 결합된 걸 찾으면 과목 테이블의 교수번호 = 교수 테이블의 교수번호인 걸 알 수 있음. 이것만 남기고 불필요한 값을 제거하면 됨. |
| 3 |  |
즉, 과목 릴레이션과 교수 릴레이션을 카티시언 프로덕트 함. 과목의 교수번호와 교수의 교수번호가 같은 레코드만 셀렉트함. |
| 4 |  |
교수 릴레이션과 학과 릴레이션에서 동일한 학과이름을 갖는 조건을 만족하는 조인 연산 결과는 다음과 같은 식으로 표현함. |
실제 컴퓨터 과학과 소속의 교수가 담당하는 과목명과 과목 코드를 추출하기 위해서는 어떻게 하면 될까?

집계 함수
| 그룹 기준이 없는 집계 연산 | 그룹 기준이 있는 집계 연산 |
| 집계 함수를 값들의 집합 또는 레코드의 집합에 적용하는 연산 | 레코드 그룹화를 위해 집계 함수 연산자 앞에 그룹화 속성을 기술 |
 |
 |
| x( ): AVG, SUM, MIN, MAX, COUNT 등의 집계 함수 A: 집계 연산을 적용할 컬럼 |
B: 그룹의 기준이 되는 컬럼 x( ): 집계 함수 A: 집계 연산을 적용할 컬럼 R: 릴레이션 |
 |
 |
집계 함수 이름 + '-distinct' : 중복된 값 제거
'방송대 컴퓨터과학과 > 데이터베이스시스템' 카테고리의 다른 글
| 방송대 데이터베이스시스템 - 6강. SQL (3) (1) | 2023.05.27 |
|---|---|
| 방송대 데이터베이스시스템 - 5강. SQL (2) (0) | 2023.05.26 |
| 방송대 데이터베이스시스템 - 4강. SQL (1) (0) | 2023.05.26 |
| 방송대 데이터베이스시스템 - 2강. 데이터베이스 모델링 (0) | 2023.05.20 |
| 방송대 데이터베이스시스템 - 1강. 데이터베이스의 이해 (1) | 2023.05.20 |



