| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 코드잇
- 코딩테스트
- Git
- 프로그래머스
- 개발자취업
- CSS
- 항해99
- 코딩테스트준비
- 엘리스sw트랙
- 오픈소스기반데이터분석
- 유노코딩
- 방송대컴퓨터과학과
- 파이썬프로그래밍기초
- JavaScript
- mongoDB
- 중간이들
- aws
- 데이터베이스시스템
- node.js
- nestjs
- 꿀단집
- Azure
- 파이썬
- TiL
- redis
- 방송대
- HTML
- 클라우드컴퓨팅
- 99클럽
- Python
- Today
- Total
배꼽파지 않도록 잘 개발해요
방송대 데이터베이스시스템 - 7강. 정규화 본문

1. 좋은 릴레이션과 나쁜 릴레이션
잘못된 데이터베이스 모델링
· 데이터의 중복
· 일관성 유지의 어려움
· 저장 공간 낭비
갱신 이상(update anomaly)
정보 삽입, 삭제, 갱신 시의 불일치로 데이터 변동 상황에 따른 이상 현상
| 삽입 이상 | 삭제 이상 | 수정 이상 |
| 레코드 추가 시 불필요한 컬럼의 값이 없이는 추가하지 못하는 경우 | 삭제 시 의도하지 않았던 다른 데이터가 삭제되는 경우 | 중복 저장된 레코드를 수정 시 모두 반영이 안되어 데이터베이스의 일관성이 깨지는 경우 |
 |
 |
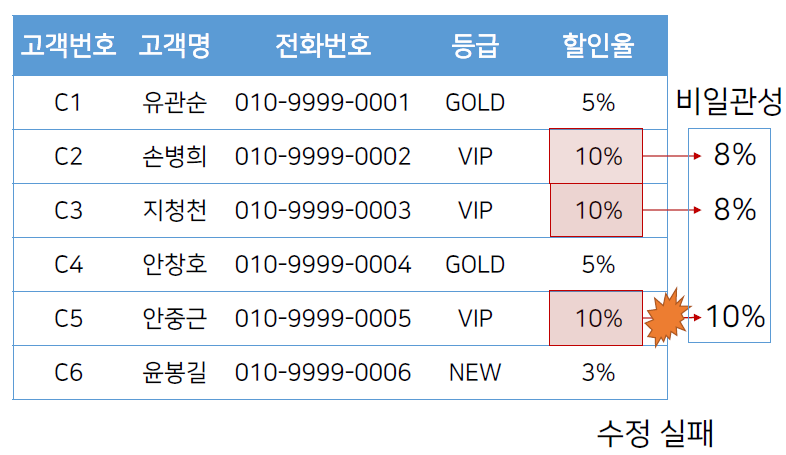 |
| 고객번호가 기본키이기 때문에 앞 속성값 3개를 모두 NULL로 만들어 놓은 상태에서는 입력이 불가능함. | 삭제하려고 하는 정보는 앞에 있는 고객정보를 삭제하지 않고서는 삭제가 불가능함. | VIP 등급의 할인율을 낮추기 위해 속성값을 수정함. 안중근 고객은 할인율 수정이 반영되지 않아서 일관성이 훼손됨. |
전체 레코드가 중복되는 건 관계형 모델에서 제약조건에 의해 불가능하지만 어떤 레코드와 레코드 사이에 특정 컬럼 또는 여러 컬럼에 거쳐서 데이터에 부분적인 중복이 발생함.
→ 정규화는 이런 부분적인 중복의 문제를 해결하기 위해 고안됨.
좋은 릴레이션의 개념
컴퓨터 프로그래머적 관점에서의 모델링
: 어떻게 데이터를 저장해야 하는가?
릴레이션의 스키마가 얼마나 효율적으로 실세계를 반영하고 있는지 평가
고려사항
· 한 릴레이션 내의 컬럼 간의 관계 분석
· 원하지 않는 데이터의 종속과 중복 제거
· 새로운 컬럼들이 데이터베이스에 추가될 때, 기존 컬럼과의 관계 수정을 최소화
 |
 |
등급과 할인율이 정해져 있음.
모든 GOLD에 대해서 5%, 모든 VIP에 대해서 항상 10%의 할인율이 있음
등급과 할인율을 모든 레코드에서 이렇게 유지할 필요가 있을까? (X)
→ 테이블을 분할
- 고객수가 많아질수록 전체 입력되는 데이터 양이 줄어듦.
- 데이터 중복과 일관성 부분에서 개선됨.
2. 함수적 종속성
함수적 종속성의 정의
릴레이션 인스턴스(특정 시점에서의 레코드의 상황)를 분석하여 속성들 간의 연관관계를 표현한 것
릴레이션의 효율성을 향상시켜 좋은 릴레이션으로 변환하는데 이용되는 중요한 개념
| 임의의 릴레이션 스키마 R 의 인스턴스 r(R) 에 포함되는 서로 다른 두 레코드 레코드r1,r2와 컬럼 집합 X 와 Y 에 대해 𝑟1𝑋=r2[𝑋]일 때 𝑟1𝑦=𝑟2[𝑦]이면 함수적 종속성 𝑋→𝑌가 성립한다 |
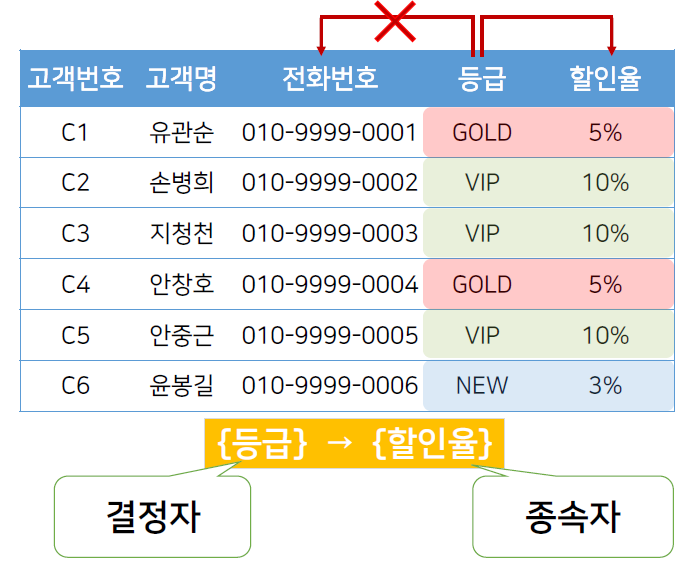
등급이 할인율을 종속한다. (O)
{등급} → {할인율}
ex. 등급이 GOLD로 같을 때 할인율 5%, VIP면 10%임.
등급이 전화번호를 종속한다. (X)
ex 등급이 'VIP'로 같은데 전화번호 속성값은 다름.
• 적법한 릴레이션(legal relation) : 관계형 데이터베이스에서 정의된 규칙과 제약 조건을 모두 만족하는 테이블
ex. 모든 레코드에 대해 등급 속성이 같을 경우 동일한 할인율이 적용됨. {등급} → {할인율}이 성립함.
• 적법하지 않은 릴레이션(illegal relation) : 관계형 데이터베이스의 규칙이나 제약 조건을 위배하는 테이블
ex. '유관순' 회원과 '윤봉길' 회원만 예외적으로 11% 할인을 해 줌.
함수적 종속성의 확장
함수적 종속성은 릴레이션의 효율성 여부에 중요한 판단기준
그러나 릴레이션의 인스턴스만으로 내재된 모든 함수적 종속성을 찾아내기 어려움
판별되지 않은 모든 함수적 종속성을 찾기 위해 추론 규칙을 사용하여 함수적 종속성을 확장
클로저(closure) : 판별된 함수적 종속성 집합으로부터 유추할 수 있는 모든 함수적 종속성 집합, F+
ex. 함수적 종속성 {고객번호} → {고객명}과 {고객명} → {전화번호}가 성립하면, {고객번호} → {전화번호}도 성립할 거라고 유추함.
함수적 종속성 추론 규칙
확정된 종속성들의 집합(클로저)로부터 논리적 모순, 오류를 배제하고 새로운 종속성을 찾아내기 위해 다음과 같은 규칙을 적용함.
암스트롱 공리(Armstrong's axiom)
- 규칙 1부터 3까지는 암스트롱의 추론규칙(Armstrong's inference rule)
- 나머지 규칙은 암스트롱 추론 규칙으로부터 유도된 규칙임.
| 1 | 재귀성 규칙 | X⊇Y이면, X→Y이다 | A = {1, 2}, B = {1} A ⊇ B가 성립하므로, A → B 역시 성립 {등급, 할인율} → {할인율} |
| 2 | 부가성 규칙 | X→Y이면, XZ→YZ이다 | A = {1, 2}, B = {1}, Z = {3} A → B가 성립하므로, AZ도 역시 BZ에 함수적으로 종속됨. A → B이면 AZ → BZ도 성립 |
| 3 | 이행성 규칙 | X→Y이고, Y →Z이면, X → Z이다. | X → Y: 학번 → 이름 (같은 학번에는 항상 같은 이름이 대응됨) Y → Z: 이름 → 학과 (같은 이름에는 항상 같은 학과가 대응됨) X → Z: 학번 → 학과 |
| 4 | 분해 규칙 | X → YZ이면, X → Y이다. | |
| 5 | 합집합 규칙 | X → Y이고, X → Z이면, X → YZ이다. | |
| 6 | 의사 이생성 규칙 | X → Y이고, WY → Z이면, WX → Z이다. |

함수적 종속성의 판별하는 방법
A가 B를 종속하는지, 즉 {A} → {B}인지 판별하는 법
- 특정 속성(A)의 속성값이 같을 때 : 다른 속성(B)의 속성값이 같아야 함.
- 특정 속성(A)의 속성값 같지 않을 때 : 다른 속성(B)의 속성값이 같든지, 말든지 상관 없음.
| 고객번호 → 고객명 | 고객번호는 고객명을 종속할까? (O) - 고객번호 속성 중 같은 속성값이 없으니까 고객명 속성 중 속성값이 같은지 여부는 상관없음. - 항상 어떤 하나의 고객번호에 대해서 고객명은 하나로만 정해짐. |
|
| 고객명 → 등급 | 고객명은 등급을 종속할까? (O) - 고객명 속성 중 '유관순'과 '안창호'는 각각 다른 속성값임. - 유관순과 안창호의 레코드를 보면 등급 속성의 속성값은 'GOLD'로 같지만 상관없음. |
|
| {고객번호, 고객명} → 할인율 | {고객번호, 고객명}은 등급을 종속할까? (O) - 고객명과 고객번호의 쌍이 같은 레코드가 없으니까 할인율 속성값이 같은지 확인할 필요가 없음. |
|
고객번호는 고객명, 등급, 할인율을 종속한다
커버와 카노니컬 커버
함수적 종속성 추론 규칙으로 확장된 클로저에는 자명한 종속성과 중복된 종속성을 포함
· 자명한 종속성 : A → A (의미가 당연)
· 중복된 종속성 : X → AB, X → B (의미가 여러번 존재)
불필요한 함수적 종속성을 제거한 표준형으로 변환 후 정규화를 수행
커버(Cover)
- 관계나 조건을 만족시키는 최소한의 요소 집합
- 주어진 함수적 종속성 집합 E에 대해 E가 함수적 종속성 집합 F+(F의 클로저)에 포함되면 E의 모든 함수적 종속성들이 F로부터 추론될 수 있으며, 이때 F가 E를 커버한다고 표현함.
카노니컬 커버(Canonical Cover)
- 함수적 종속성을 나타내는 최소한의 함수적 종속성 집합
- F+에 존재하는 모든 함수적 종속성을 커버할 수 있는 최소한의 함수적 종속성들로만 이루어진 집합
카노니컬 커버가 의미적 중복없이 표준형으로 표현되기 위해서는 아래 세 가지 표준형 조건을 만족해야 함.
표준형 조건
- F의 모든 함수적 종속성의 오른편 속성(종속자)은 반드시 1개
ex. {x, y} → {z} (O), {x} → {a, b} (X)
- F에서 X → A를 X의 진부분집합 Y에 대하여 Y → A로 교체했을 때, 그 집합이 F와 동등한 집합이 불가능
ex. X에 3개의 컬럼이 있어서 2개의 컬럼만으로도 A를 종속할 수 있다고 하면 굳이 X는 A를 종속한다라고 하는 형태는 필요가 없음.
- F에서 어떤 함수적 종속성을 제거했을 때, 그 집합이 F와 동등한 집합이 불가능
ex. 뺐는데도 의미적으로 동일하다면 애초에 불필요한 것임.
3. 정규화
정규형(Normal Form)
이상 현상을 최소화하도록 특정 조건을 갖춘 릴레이션의 형식
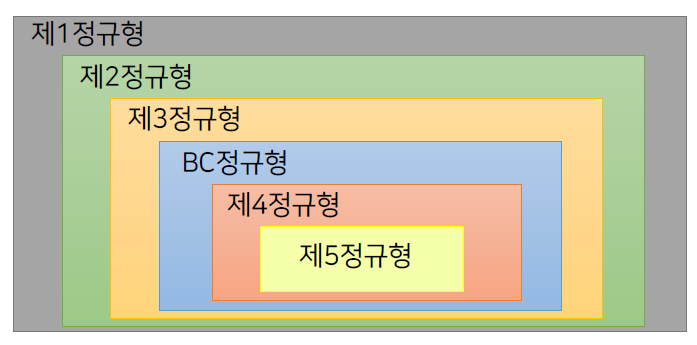 |
제2정규형. 제3정규형, BC정규형 : 함수적 종속성 기준으로 구조화 제4정규형 : 다중치 종속성 기준으로 구조화 제5정규형 : 조인 종속성에 기반하여 구조화 제4정규형, 제5정규형은 현실적으로 거의 사용하지 않음. |
• 제1정규형 : 모든 속성이 원자값을 가짐
• 제2정규형 : 기본키가 아닌 속성들이 기본키에 대해 완전 종속임(기본키에 대한 부분적 종속 제거)
• 제3정규형 : 기본키가 아닌 속성들이 어떤 키에도 이행적으로 종속하지 않음(이행적 종속 제거)
• BC정규형(보이스-코드) : X → A 형태의 모든 함수적 종속성에 대해 X(결정자)가 R의 수퍼키이면 만족
정규화(Normalization)
특정 정규형의 조건을 만족하도록 릴레이션과 속성을 재구성하는 과정
정규화는 정규형을 만들어내기 위한 것
· 데이터베이스 내 모든 릴레이션을 효과적으로 표현
· 보다 간단한 관계 연산에 기초하여 검색 알고리즘을 효과적으로 작성할 수 있도록 지원
· 바람직하지 않은 삽입, 수정, 삭제 등의 이상 발생 방지
· 새로운 형태의 데이터가 삽입될 때 릴레이션 재구성의 필요성을 축소
제1정규형
가장 조건이 단순한 정규형
관계형 모델에 조건에 따라 자동 적용되는 정규형
릴레이션 스키마에서 정의된 모든 속성의 도메인이 원자값을 갖는 상태
선박이 항구에 정박하기 위해 정밀한 작업이 요구
풍향과 풍속, 파도와 안개 상황 등을 고려
단순히 수신호 뿐만 아니라 소형 배들로 정박하려는 대형 배를 밀어 안전하게 위치시키는 작업을 고려
도선 : 배를 도크에 안전하게 접안시키고 항로로 인도하는 일을 하는 사람
도크 : 선박의 건조, 수리, 계선, 하역 작업 등을 위해 축조된 설비 및 시설의 총칭
 |
 |
함수적 종속성
| 임의의 릴레이션 스키마 R 의 인스턴스 r(R) 에 포함되는 서로 다른 두 레코드 𝑡1,𝑡2와 속성 집합 X 와 Y 에 대해 𝑡1𝑋=𝑡2[𝑋]일 때 𝑡1𝑦=𝑡2[𝑦]이면 함수적 종속성 𝑋→𝑌가 성립한다 |
 |
 |
판단 기준 : 같을 때만 같으면 됨!
도크번호는 도크관리자를 종속한다.
목적은 담당도선사를 종속한다.
목적은 도크번호를 종속한다.
함수적 종속성 다이어그램(Functional Dependency Diagram, FDD)
릴레이션 내의 속성간의 종속 관계를 직관적이고 이해하기 쉽게 도식화 한 표현 방식
- 직사각형 : 속성 또는 속성 집합
- 화살표 : 함수적 종속성
 |
 |
도크번호, 입항시간 : 키 속성(기본키)
도크번호와 입항시간이 출항시간, 목적, 담당도선사를 종속한다.
목적은 도크번호만 종속한다.
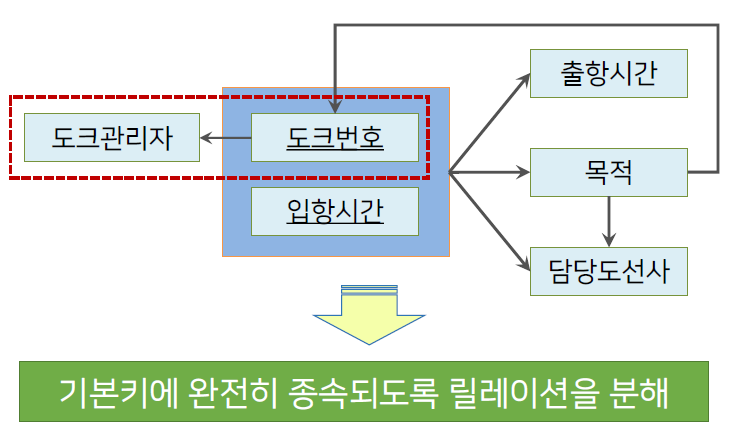
제2정규형
릴레이션이 제1정규형을 만족하고 기본키의 부분집합이 특정 속성을 종속하고 있지 않은 상태
주어진 릴레이션의 인스턴스가 기본키가 아닌 속성들이 기본키에 완전히 종속되어 있는 상태
 |
 |
출항시간, 목적, 담당도선사는 키에 완전 종속됨.
도크관리자는 키의 일부분인 도크번호에 의해 종속됨.
도크관리자는 키에 부분적으로 종속됨.
→ 기본키에 완전히 종속되도록 릴레이션을 분해
무손실 분해(lossless decomposition)
- 정보 손실이 없으며 조인 시 원래의 릴레이션으로 복원 가능한 분해
- 스키마 R에 함수적 종속성 X → Y가 존재하고 X∩Y=∅이면, R을 R-Y와 XY로 분해
도크관리 릴레이션 무손실 분해
- {도크번호} → {도크관리자}
- {도크번호} ∩ {도크관리자} = ∅
- 도크관리 - {도크관리자},{도크번호, 도크관리자}
 |
 |
제3정규형
릴레이션이 제2정규형을 만족하고, 기본키가 아닌 속성들이 어떤 키에도 이행적으로 종속되지 않은 상태
이행적 종속성 : X → Y이고 Y → Z이면 X → Z이다
 |
 |
{도크번호, 입항시간} → {목적}
{목적} → {담당도선사}
{도크번호, 입항시간} → {담당도선사}
 |
 |
BC정규형(보이스-코드)
릴레이션이 제3정규형을 만족하고 릴레이션에 성립하는 X → Y 형태의 모든 함수적 종속성에 대하여 X(결정자)가 수퍼키인 상태
입출항관리 릴레이션의 함수적 종속성
· {도크번호, 입항시간} → {목적}
· {도크번호, 입항시간} → {출항시간}
· {목적} → {도크번호} : 목적은 기본키가 아니면서도 수퍼키가 아닌 일반 속성임.
 |
 |
목적이 키본키인 도크번호를 대체하고, 목적이 도크번호를 데리고 나옴.
종속자인 도크번호가 나오게 되고, 그 부분을 목적이 대체함.

이 과정은 무손실 분해이기 때문에 정규화까지 통해서 만들어진 네 개의 릴레이션을 모두 조인하면 원래의 릴레이션을 만들어냄.
역정규화(Denormalization)
정규화
- 릴레이션 분할을 통해 데이터의 중복성을 최소화 하는 과정
- 사용 과정에서 많은 조인연산을 유발
역정규화
- 정규화의 반대 과정
- 정규화를 통해 분리되었던 릴레이션을 통합하는 재조정을 수행하고 정보의 부분적 중복을 허용하는 기법
- 데이터 접근 성능을 개선 목적
- 정규화되지 않은 스키마와 역정규화 스키마는 구별
역정규화 방법
| 릴레이션의 병합 | 특정한 두 릴레이션 간의 잦은 참조로 조인이 이루어져 읽기 응답속도가 저하될 경우 두 릴레이션을 병합 1:N 관계를 갖는 두 릴레이션의 경우 N쪽의 모든 데이터를 1에 통합하여 저장 ex. '과목' 릴레이션을 조회할 때 '교수번호'는 의미가 없고, '교수이름'만 중요함. 매번 '과목'과 '교수' 릴레이션을 조인하여 정보를 얻기 (X) → '교수 이름' 속성을 과목에 추가 |
| 릴레이션의 수직분할 | 빈번하게 접근하는 속성과 접근이 일어나지 않는 속성을 두 릴레이션으로 나누어 저장 자주 조회되는 속성으로 이루어진 릴레이션과 그렇지 않은 속성들의 릴레이션으로 나누어 저장 |
| 릴레이션의 수평분할 | 속성이 아닌 레코드를 기준으로 분할 ex. 학생 레코드를 학과별로 수평 분할하여 물리적으로 저장 |
| 유도 속성 추가 | 유도속성: 원래 설계한 릴레이션에는 없는 속성이지만 업무 효율을 위해서 추가하는 속성 ex. '생년월일'에서 '나이'를 도출할 수 있는데, 이때 추가한 '나이' 속성이 유도속성임. |
역정규화 장단점
- 장점 : 읽기 성능(SELECT문)이 상향됨.
- 단점 : 중복 데이터 저장을 위한 추가 공간 요구, 중복된 데이터의 일관성을 유지하기 위해 쓰기 성능(INSERT문, UPDATE문, DELETE문)의 속도가 저하됨.
'방송대 컴퓨터과학과 > 데이터베이스시스템' 카테고리의 다른 글
| 방송대 데이터베이스시스템 - 9강. 데이터 저장과 파일 (1) | 2023.05.28 |
|---|---|
| 방송대 데이터베이스시스템 - 8강. 연습문제 풀이 1 (1-7강) (1) | 2023.05.28 |
| 방송대 데이터베이스시스템 - 6강. SQL (3) (1) | 2023.05.27 |
| 방송대 데이터베이스시스템 - 5강. SQL (2) (0) | 2023.05.26 |
| 방송대 데이터베이스시스템 - 4강. SQL (1) (0) | 2023.05.26 |



