
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 파이썬
- mongoDB
- Git
- Azure
- 엘리스sw트랙
- 항해99
- 데이터베이스시스템
- 개발자취업
- Python
- 방송대
- TiL
- aws
- 코딩테스트준비
- 중간이들
- CSS
- 클라우드컴퓨팅
- 유노코딩
- 프로그래머스
- JavaScript
- 99클럽
- 방송대컴퓨터과학과
- 꿀단집
- 오픈소스기반데이터분석
- HTML
- node.js
- nestjs
- 코드잇
- 코딩테스트
- 데이터분석
- 파이썬프로그래밍기초
- Today
- Total
배꼽파, 오늘도 배꼽 대신 데이터를 판다
NestJS + Mongoose: Feed 썸네일 추출 과정에서 겪은 문제와 해결기 본문
프로젝트에서 여행 피드(Feed)를 조회할 때, 여행 계획(TravelPlan)과 그 하위 일정(DailyPlan, DailySchedule)을 populate하여 thumbnailUrl을 뽑아내는 기능을 구현하고 있었다.
그런데 실제 데이터베이스에는 DailySchedule이 분명 존재하는데도, API 응답에서는 thumbnailUrl이 null만 나오는 문제가 발생하였다.
문제 1. thumbnailUrl이 계속 null만 나옴
증상
- Atlas 에서는 TravelPlan의 dailyPlans 안에 DailySchedule이 잘 들어가 있음.
- 그런데 로그 찍어보면 항상 빈 배열.
- 결과적으로 thumbnailUrl이 null만 반환됨.
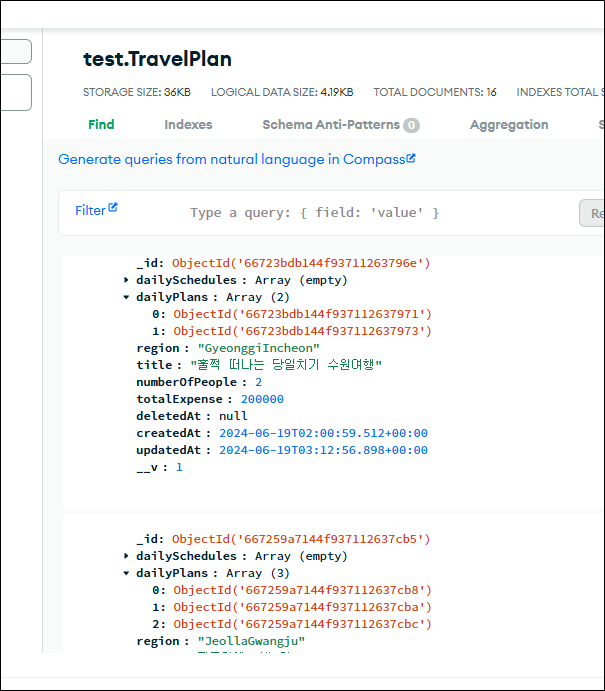
======= travelPlan['dailyPlans'] []
=============allDailySchedules []
========= travelPlan {
dailySchedules: [],
dailyPlans: [],
region: 'Jeju',
title: '오랜만에 제주여행 !',
numberOfPeople: 4,
totalExpense: 0,
deletedAt: null,
_id: new ObjectId('6670fc536a581c92fdafb66c'),
createdAt: 2024-06-18T03:17:39.190Z,
updatedAt: 2024-06-18T03:17:39.190Z,
__v: 0, id: '6670fc536a581c92fdafb66c' }
========= travelPlan.dailyPlans []
========= travelPlan['dailyPlans'] []
=============allDailySchedules []
원인
feed.travelPlan이 상황에 따라
- ObjectId
- 얕은 plain object
- populate된 document
등 섞여서 들어오기 때문에, 항상 deep-populate가 보장되지 않았다.
결국 DailyPlan → DailySchedule이 비어 있어서 썸네일 추출이 실패한 것이다.
해결책
분기(if object → populate, if id → findById)를 다 없애고, 항상 _id를 뽑아내서 findById().populate(...)를 실행하도록 강제했다. 이렇게 하면 입력이 어떤 형태로 들어와도 결과는 항상 deep-populate 된 문서로 보장된다.
// feed.travelPlan이 뭐든 _id만 뽑아내서 처리
const tpAny = feed.travelPlan as any;
const tpId =
typeof tpAny === 'string'
? tpAny
: tpAny?._id
? String(tpAny._id)
: (tpAny as ObjectId)?.toString?.();
if (!tpId) return null;
const travelPlan = await this.travelPlanModel.findById(tpId).populate([
{
path: 'dailyPlans',
model: 'DailyPlan',
select: 'date dateType dailySchedules',
populate: {
path: 'dailySchedules',
model: 'DailySchedule',
select: 'imageUrl isThumbnail',
},
},
{
path: 'dailySchedules',
model: 'DailySchedule',
select: 'imageUrl isThumbnail',
},
]);
공식문서 참고
- Mongoose Populate 공식 문서: 배열 형태의 populate 옵션과 nested populate 방법
- NestJS Mongoose 공식 문서: @InjectModel로 모델 주입 후 서비스 계층에서 DB 접근 패턴
문제 2. 응답에서 TravelPlan 전체가 노출됨
증상
응답 객체에서 return 부분에서 travelPlan을 제외했는데도, TravelPlan 전체 데이터가 그대로 내려왔다.
그 결과 API 응답이 불필요하게 무거워지고, 속도도 느려졌다.
return {
feedId: feed._id.toString(),
travelPlanId: travelPlan['_id'].toString(),
// travelPlan, ❌ 뺐는데도 여전히 travelPlan이 응답에 포함됨
...
}
원인
문제는 FeedService.findByIds 단계에서 이미 populate된 travelPlan이 붙은 상태로 들어왔기 때문이다.
따라서 FeedExtractor에서 return에서 travelPlan을 빼더라도, 상위 Feed 문서가 가진 travelPlan 필드는 계속 직렬화되어 내려왔던 것.
→ 즉, DTO를 깎아도 다른 경로에서 원시 문서가 그대로 응답에 섞여 들어오고 있었던 것.
해결책
아래 단일 패턴으로 통일했다.
- getPaginatedFeeds는 id만 가져온다.
- 그 id 배열로 findByIds를 다시 조회(필요한 populate만)
- FeedExtractor.extractFeeds()로 DTO 배열을 만든다.
- 새 페이지 객체를 만들어 metadata + DTO 배열만 반환한다.
(원본 data를 덮어쓰지 않고 아예 새로 작성)
// 서비스 계층 공통 패턴 (OurTripService / MyTripService)
const pageIds = await this.feedService.getPaginatedFeeds(pageNumber, pageSize, criteria, sort);
// 1) id만 있는 배열
const ids = (pageIds.feeds.data ?? []).map(d => String((d as any)._id));
// 2) 실제 문서 재조회 (findByIds 내부에서 travelPlan 최소 select/populate)
const docs = await this.feedService.findByIds(ids);
// 3) 정제/추출 (항상 DTO 배열)
const data = await this.feedExtractor.extractFeeds(docs, userId ?? undefined);
// 4) 새 페이지 객체로 조립 → 원시 문서 누수 방지
return { success: true, feeds: { metadata: pageIds.feeds.metadata, data } };이렇게 하니 아무리 다른 경로에서 populate가 되어도,
마지막에 응답으로 나가는 건 오로지 DTO 배열뿐이라 travelPlan이 더 이상 섞여 나오지 않았다.
최종적으로 응답은 깔끔하게 가벼워졌다.
공식문서 근거
- NestJS – DTOs:
“DTOs are objects that define how data will be sent over the network.”
→ 네트워크 응답 형식은 DTO로 일원화해야 하며, 원시 문서가 새어 나가면 안 됨. - NestJS – Providers/Services:
서비스 계층을 분리하고, 한 계층에서 응답 조립의 단일 책임을 갖는 것이 바람직. - Mongoose Populate:
필요 시점에만 최소한의 필드로 populate. (select 옵션 활용)
문제 3. Pagination 변경 후 타입 에러
현상
getPaginatedFeeds를 “id만 반환”하도록 바꾸니, feeds.data가 { _id: string }[]가 되고,
여기에 DTO 배열(ExtractedFeed[])을 그대로 넣으면 타입 충돌이 발생했다.
Type 'ExtractedFeed[]' is not assignable to type '{ _id: string }[]'
해결
— 타입과 응답을 맞춘다
2번 해결책과 동일한 흐름으로, 새 페이지 객체를 만들 때
feeds: { metadata, data: ExtractedFeed[] } 로 정확한 구조로 반환한다.
즉, “id 페이지”와 “DTO 페이지”는 다른 타입의 결과이므로, 아예 새로 생성하는 것이 맞다.
const pageIds = await this.feedService.getPaginatedFeeds(pageNumber, pageSize, criteria, sort);
const ids = (pageIds.feeds.data ?? []).map(d => String((d as any)._id));
const docs = await this.feedService.findByIds(ids);
const data = await this.feedExtractor.extractFeeds(docs, userId ?? undefined);
// 타입 충돌 없이 새로 조립
return { success: true, feeds: { metadata: pageIds.feeds.metadata, data } };
공식문서 근거
- Mongoose Aggregate: $facet로 meta/data를 나누거나 최소 페이로드(id)만 먼저 가져오는 패턴이 일반적.
이후 별도 쿼리로 필요한 populate/가공을 적용해 최종 응답을 생성. - NestJS – 설계 원칙:
레이어(서비스) 간 역할을 분리하고, 최종 응답을 조립하는 책임을 단일화하면 타입 안정성과 유지보수성이 높아짐.
문제 4. 다시 쿼리 수 증가!

하지만 이렇게 해서 문제는 잘 해결되었으나, 썸네일이 나오도록 고치다보니 쿼리 수가 늘어나면서 응답 속도 지연이 발생했다.
( 46.96ms → 1.06s )
원래 계획으로는 findByIds에서 populate를 하면 travelPlan -> dailySchedules까지 함께 populate되어 썸네일 추출이 가능해져야 했다.
하지만 populate가 제대로 동작하지 않는 것을 보니, 애초에 저장된 데이터 구조가 populate와 호환되지 않아서 발생한 문제일 가능성이 있을수도?
정확한 원인을 파악하려면 더 깊이 있는 분석이 필요하지만,
현재로서는 기능이 정상적으로 동작하고 있기 때문에 이 상태로 마무리하기로 했다.
완벽한 해결책을 찾지 못한 아쉬움은 있지만, 프로젝트를 완성하는 것이 더 중요하다고 판단했다.
취업 후 여유가 생기면 이 부분을 다시 연구해봐야겠다.
'BackEnd > Database' 카테고리의 다른 글
| Mongoose N+1 문제 해결로 8배 성능 향상 (0) | 2025.08.26 |
|---|---|
| N + 1 쿼리 MySQL로 직접 눈으로 확인해보자 (0) | 2025.08.26 |
| stateful과 stateless (0) | 2024.12.29 |
| [Redis] Redis 클라이언트는 기본적으로 로컬 Redis 서버에 연결됨 (0) | 2024.09.10 |
| [Redis] Redis Cloud와 Redis Insignt 차이점 및 사용해보기 (0) | 2024.09.10 |


