
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 오픈소스기반데이터분석
- mongoDB
- 개발자취업
- 중간이들
- 파이썬프로그래밍기초
- 꿀단집
- HTML
- 프로그래머스
- 데이터베이스시스템
- TiL
- 클라우드컴퓨팅
- 방송대컴퓨터과학과
- Python
- Git
- 코드잇
- 항해99
- 데이터분석
- Azure
- node.js
- aws
- 파이썬
- 코딩테스트준비
- 방송대
- 코딩테스트
- CSS
- nestjs
- JavaScript
- 엘리스sw트랙
- 99클럽
- 유노코딩
- Today
- Total
배꼽파, 오늘도 배꼽 대신 데이터를 판다
기술통계 정리 - 수식과 그래프로 이해하기 본문

기술통계는 데이터를 요약해서 “이 데이터가 어떤 모양인지” 파악하는 방법이다.
단순히 평균을 구하는 것이 아니라,
- 데이터가 가운데 몰려 있는지
- 한쪽으로 치우쳤는지
- 이상하게 튀는 값이 있는지
- 대표값으로 평균을 써도 되는지
이런 걸 판단하기 위한 기초 작업이다.
1. 평균: 전체 값을 고르게 나눴을 때의 값
평균은 가장 익숙한 대표값이다.
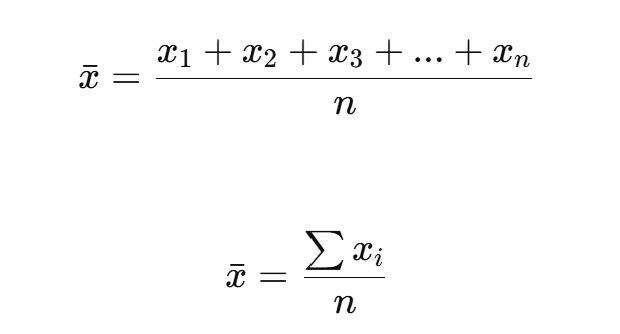
예를 들어 시험 점수가 다음과 같다고 하자.
scores = [60, 70, 75, 80, 95]평균은 다음과 같다.

즉 평균 점수는 76점이다.
하지만 평균은 이상치에 약하다.
scores = [60, 70, 75, 80, 200]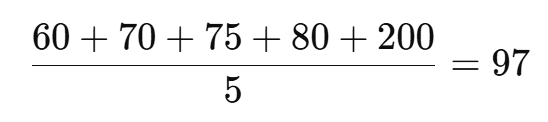
평균은 97점이지만, 대부분의 값은 60~80점 사이에 있다.
이때 평균만 보면 실제 데이터의 분위기를 잘못 이해할 수 있다.
2. 중앙값: 가운데 있는 값
중앙값은 데이터를 크기순으로 정렬했을 때 가운데 있는 값이다.
scores = [60, 70, 75, 80, 200]중앙값은 75다.
평균은 97인데 중앙값은 75다.
이 차이가 크다는 것은 데이터에 극단값이 있거나, 한쪽으로 치우쳐 있을 가능성이 있다는 뜻이다.
3. 사분위수와 IQR
사분위수는 데이터를 4등분한 값이다.
- Q1: 1사분위수, 하위 25%
- Q2: 2사분위수, 중앙값, 하위 50%
- Q3: 3사분위수, 하위 75%
- Q4: 최댓값 쪽, 전체 범위의 끝
예를 들어 데이터가 다음과 같다고 하자.
data = [1, 3, 5, 7, 9, 11, 13, 15]- Q1 = 4
- Q2 = 8
- Q3 = 12
IQR은 Q3에서 Q1을 뺀 값이다.
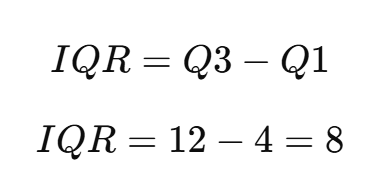
IQR은 데이터의 가운데 50%가 얼마나 퍼져 있는지 보여준다.
4. IQR로 이상치 판단하기
이상치 후보는 보통 아래 기준으로 본다.
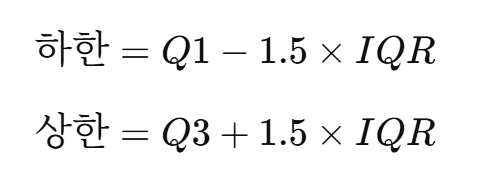
위 예시에서

따라서 -8보다 작거나 24보다 큰 값은 이상치 후보가 된다.
여기서 중요한 건 “무조건 제거”가 아니다.
이상치는 세 가지로 나눠서 봐야 한다.
| 구분 | 예시 | 처리 |
| 입력 오류 | 매출 500을 5000으로 잘못 입력 | 수정 또는 제거 |
| 특수한 사건 | 이벤트 기간 매출 급증 | 별도 분석 |
| 실제 극단값 | 고연봉자, VIP 고객 구매액 | 유지 후 해석 주의 |
5. 히스토그램: 값이 어디에 몰려 있는지 보기
히스토그램은 데이터를 구간으로 나눠서 각 구간에 값이 몇 개 있는지 보여준다.
예를 들어 시험 점수가 다음처럼 분포한다고 하자.
| 점수 구간 | 학생 수 |
| 50~60 | 5명 |
| 60~70 | 20명 |
| 70~80 | 45명 |
| 80~90 | 25명 |
| 90~100 | 5명 |
이걸 그래프로 그리면 가운데가 높은 산 모양이 된다.
50~60 █████
60~70 ████████████████████
70~80 █████████████████████████████████████████████
80~90 █████████████████████████
90~100 █████이런 모양이면 대부분의 점수가 70~80점 근처에 몰려 있다는 뜻이다.
6. 파이썬으로 히스토그램 그리기
import matplotlib.pyplot as plt
scores = [55, 60, 62, 65, 68, 70, 72, 73, 75, 76,
78, 80, 82, 85, 88, 90, 92]
plt.hist(scores, bins=5)
plt.title("Exam Score Histogram")
plt.xlabel("Score")
plt.ylabel("Frequency")
plt.show()히스토그램을 볼 때는 이 세 가지를 먼저 본다.
- 가운데 몰려 있는가?
- 한쪽으로 꼬리가 긴가?
- 혼자 튀는 값이 있는가?
7. KDE: 히스토그램을 부드럽게 본 그래프
히스토그램은 구간을 어떻게 나누느냐에 따라 모양이 달라진다.
그래서 분포를 더 부드럽게 보고 싶을 때 KDE를 쓴다.
KDE는 Kernel Density Estimation의 약자다.
가지고 있는 데이터만으로 전체 분포 모양을 추정하는 방법이다.
쉽게 말하면,
히스토그램은 막대그래프
KDE는 부드러운 곡선
이라고 보면 된다.
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gaussian_kde
scores = [55, 60, 62, 65, 68, 70, 72, 73, 75, 76,
78, 80, 82, 85, 88, 90, 92]
density = gaussian_kde(scores)
x = np.linspace(min(scores), max(scores), 200)
plt.plot(x, density(x))
plt.title("Exam Score KDE")
plt.xlabel("Score")
plt.ylabel("Density")
plt.show()KDE는 실제 정답이 아니라 추정이다.
그래서 “대략 이런 모양이구나” 정도로 이해하는 게 좋다.
8. 정규분포: 가운데가 가장 높은 종 모양
정규분포는 가운데에 데이터가 가장 많이 몰리고, 양쪽으로 갈수록 데이터가 적어지는 분포다.
█
█████
█████████
█████████████
█████████████████
█████████████
█████████
█████
█정규분포에서는 보통 아래와 같다.

시험 점수, 키, 측정 오차 같은 데이터는 정규분포에 가까운 경우가 많다.
다만 모든 데이터가 정규분포를 따르는 건 아니다.
연봉, 매출, 조회수, 구매금액 같은 데이터는 보통 한쪽으로 치우치는 경우가 많다.
9. 왜도: 분포가 한쪽으로 치우친 정도
왜도는 데이터가 어느 방향으로 치우쳤는지 나타낸다.
오른쪽으로 치우친 분포
████████
██████
████
██
█
█오른쪽 꼬리가 길다.
- right-skewed
- positive skewed
- 왜도 > 0
예시:
salary = [2500, 2700, 2800, 3000, 3200, 3500, 9000]대부분은 2000~3000대인데, 9000이라는 큰 값 하나가 오른쪽 꼬리를 만든다.
이때 평균은 중앙값보다 커진다.
왼쪽으로 치우친 분포
█
█
██
████
██████
████████왼쪽 꼬리가 길다.
- left-skewed
- negative skewed
- 왜도 < 0
예시:
scores = [20, 70, 75, 80, 85, 90, 95]대부분 높은 점수인데 20점 하나가 왼쪽 꼬리를 만든다.
10. 왜도 계산 코드
import pandas as pd
salary = [2500, 2700, 2800, 3000, 3200, 3500, 9000]
s = pd.Series(salary)
print("평균:", s.mean())
print("중앙값:", s.median())
print("왜도:", s.skew())해석:
평균 > 중앙값이면 오른쪽 꼬리 가능성
평균 < 중앙값이면 왼쪽 꼬리 가능성
왜도 > 0이면 오른쪽 치우침
왜도 < 0이면 왼쪽 치우침11. 첨도: 분포가 얼마나 뾰족한가
첨도는 데이터가 가운데에 얼마나 몰려 있는지, 그리고 꼬리가 얼마나 두꺼운지 보는 지표다.
첨도가 높으면 다음과 같은 느낌이다.
█
█
█
█████
█████
█████████중앙에 값이 많이 몰려 있고, 동시에 극단값이 나타날 가능성도 커진다.
첨도가 낮으면 더 완만하다.
█████
█████████
█████████████
█████████████
█████████
█████파이썬에서는 이렇게 구한다.
import pandas as pd
data = [45, 48, 49, 50, 50, 51, 52, 55, 100]
s = pd.Series(data)
print("첨도:", s.kurt())첨도는 혼자 보기보다 히스토그램, 박스플롯과 같이 보는 게 좋다.
12. Box Plot: 사분위수와 이상치를 한 번에 보기
Box Plot은 기술통계 요약 그래프다.
이상치
o
최솟값 ────[ Q1 | 중앙값 | Q3 ]──── 최댓값
<---- IQR ---->Box Plot에서 볼 수 있는 것:
- 중앙값
- Q1
- Q3
- IQR
- 이상치 후보
파이썬 코드:
import matplotlib.pyplot as plt
salary = [2500, 2700, 2800, 3000, 3200, 3500, 9000]
plt.boxplot(salary)
plt.title("Salary Box Plot")
plt.ylabel("Salary")
plt.show()이 그래프에서 9000은 다른 값들과 너무 멀리 떨어져 있으므로 이상치처럼 보인다.
하지만 실제 고연봉자일 수 있다.
그러면 삭제하면 안 된다.
13. 실생활 예시 1 — 시험 점수
scores = [55, 60, 62, 65, 68, 70, 72, 73, 75, 76,
78, 80, 82, 85, 88, 90, 92]이 데이터는 비교적 고르게 퍼져 있고, 극단값이 크지 않다.
import pandas as pd
s = pd.Series(scores)
print(s.describe())
print("왜도:", s.skew())
print("첨도:", s.kurt())해석:
- 평균과 중앙값이 비슷하면 평균 사용 가능
- 왜도가 0에 가까우면 큰 치우침 없음
- 히스토그램이 가운데 높은 모양이면 정규분포에 가까움
14. 실생활 예시 2 — 연봉
salary = [2500, 2700, 2800, 3000, 3200, 3500, 9000]이 데이터는 평균과 중앙값 차이가 크다.
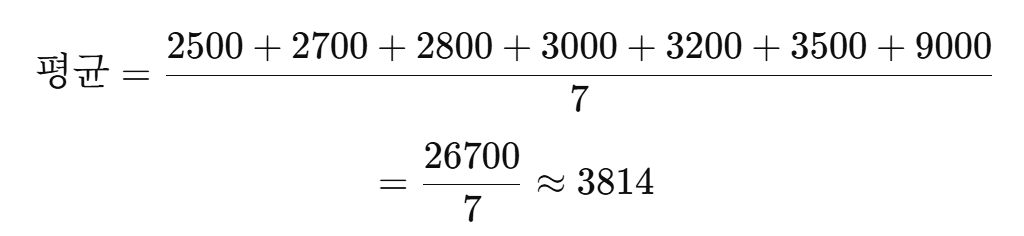
중앙값은 3000이다.
평균은 3814지만, 실제로 대부분은 2500~3500 사이에 있다.
따라서 “일반적인 연봉”을 말할 때는 평균보다 중앙값이 더 적절할 수 있다.
15. 실생활 예시 3 — 매출
sales = [480, 500, 510, 495, 505, 520, 490, 1500]이 데이터에서 1500은 다른 값보다 훨씬 크다.
평균:

중앙값:
정렬하면
480, 490, 495, 500, 505, 510, 520, 1500중앙값은 가운데 두 값의 평균이다.
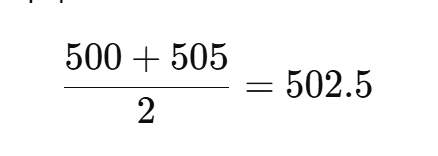
평균은 625지만 중앙값은 502.5다.
즉, 1500이라는 큰 값 하나가 평균을 올렸다.
여기서 중요한 질문은 이거다.
- 1500은 이벤트 매출인가?
- 입력 오류인가?
- 실제로 자주 발생 가능한 값인가?
이상치는 숫자만 보고 제거하면 안 된다.
맥락을 보고 판단해야 한다.
최종 정리
기술통계에서 가장 중요한 건 계산이 아니다.
계산은 파이썬, 엑셀, 계산기가 한다.
중요한 건 이 질문들이다.
- 평균과 중앙값이 비슷한가?
- 데이터가 한쪽으로 치우쳤는가?
- 이상치가 있는가?
- 히스토그램은 어떤 모양인가?
- KDE로 봤을 때 분포가 부드럽게 이어지는가?
- Box Plot에서 튀는 값이 보이는가?
- 평균을 대표값으로 써도 되는가?
기술통계는 복잡한 분석을 하기 전, 데이터를 처음 이해하는 단계다.
데이터의 모양을 보지 않고 평균만 계산하면 숫자는 맞아도 해석은 틀릴 수 있다.
'실전 기술 활용 > 데이터 분석' 카테고리의 다른 글
| 교육 효과 분석 2편: 분석 결과를 Streamlit 대시보드로 만들기 (0) | 2026.06.03 |
|---|---|
| 교육 효과 분석 1편: 대응표본 t-test로 검증한 교육 전후 변화 (0) | 2026.06.03 |
| 추론 통계 기본 개념 정리 - 표준편차, 신뢰구간, p-value까지 (0) | 2026.06.03 |


