
- 분류 전체보기 (254)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 데이터베이스시스템
- 오픈소스기반데이터분석
- 파이썬프로그래밍기초
- mongoDB
- 엘리스sw트랙
- 방송대
- 99클럽
- JavaScript
- 꿀단집
- TiL
- 항해99
- 중간이들
- 유노코딩
- 프로그래머스
- Azure
- 파이썬
- 코딩테스트
- 개발자취업
- HTML
- 코딩테스트준비
- aws
- Git
- 방송대컴퓨터과학과
- Python
- CSS
- 클라우드컴퓨팅
- nestjs
- node.js
- 코드잇
- 데이터분석
- Today
- Total
배꼽파, 오늘도 배꼽 대신 데이터를 판다
연말 설문 분석 1편: Python과 Pandas로 평균 만족도 뒤의 저만족 신호 분석하기 본문

평균 만족도가 높아도 문제는 숨어 있을 수 있다
설문 평균 뒤에 가려진 저만족 신호를 코드로 확인한 과정
만족도 설문은 보통 평균부터 본다.
문제는 평균이 높아도, 일부 집단의 반복적 불편은 충분히 가려질 수 있다는 점이다.
이번 분석은 그 평균 뒤 구조를 다시 보는 작업이었다.
핵심은 3가지였다.
- 설문 A/B 데이터를 하나로 합치기
- 평균 외에 저만족 지표 만들기
- 세그먼트별 차이를 통계적으로 확인하기
이번 글에서 구현한 것
- 설문 데이터를 하나의 마스터 테이블로 정리했다.
- 저만족 / 심각 저만족 플래그를 만들었다.
- 세그먼트별 평균과 비율을 비교했다.
- ANOVA와 카이제곱으로 집단 차이를 확인했다.
1. 왜 평균만으로는 부족했나
이번 프로젝트의 출발점은 단순했다.
전체 평균은 높게 나오지만, 실제 운영에서는 특정 집단의 불편이 반복된다는 체감이 있었다.
| 구분 | 기존 방식 | 이번 분석 |
| 만족도 해석 | 평균 점수 중심 | 평균 + 편차 + 저만족 비율 |
| 집단 비교 | 전체 응답 기준 | 이용 목적 세그먼트 기준 |
| 텍스트 활용 | 참고용 | 행동 신호로 해석 |
| 목표 | 전반 경향 확인 | 숨은 리스크 식별 |
2. 먼저, 데이터를 하나로 합쳤다
실무 설문 데이터는 소스가 여러 개면 컬럼 구조가 조금씩 다르다.
그래서 분석 전에 공통 스키마를 맞추는 작업이 먼저 필요하다. 실제 프로젝트도 데이터 A 750건, B 250건을 결합해 분석했다.
사용한 주요 컬럼
| 컬럼 | 의미 |
| response_id | 응답 ID |
| source | 설문 출처 |
| cat_01 | 이용 목적 세그먼트 |
| sat_01 ~ sat_06 | 만족도 문항 |
| text_01 | 주관식 의견 |
코드 1. 설문 A/B 결합
import pandas as pd
import numpy as np
a_df = pd.read_excel("survey_A_mock.xlsx")
b_df = pd.read_excel("survey_B_mock.xlsx")
base_cols = ["response_id", "source", "cat_01", "cat_02", "cat_03", "cat_06"]
score_cols = ["sat_01", "sat_02", "sat_03", "sat_04", "sat_05", "sat_06"]
text_cols = ["text_01"]
master_cols = base_cols + score_cols + text_cols
for col in master_cols:
if col not in a_df.columns:
a_df[col] = np.nan
if col not in b_df.columns:
b_df[col] = np.nan
a_df = a_df[master_cols]
b_df = b_df[master_cols]
df = pd.concat([a_df, b_df], ignore_index=True)
print(df.shape)
df.head()핵심은 concat()보다 결합 전 컬럼 통일이다.
3. 평균 말고 어떤 지표를 봤나
이번 분석의 핵심은 복잡한 모델보다 지표 설계였다.
평균 외에 표준편차, 저만족 비율, 심각 저만족 비율, 주관식 작성률, 불만 표현 비율 등을 사전 정의했다.
| 지표 | 의미 |
| 평균 만족도 | 전체 수준 확인 |
| 표준편차 | 경험 일관성 확인 |
| 저만족 비율 | 3점 이하 항목 존재 여부 |
| 심각 저만족 비율 | 2점 이하 항목 존재 여부 |
| 주관식 작성률 | 의견 작성 행동 |
| 불만 표현 비율 | 개선 요구 강도 |
코드 2. 저만족 / 심각 저만족 플래그 생성
df[score_cols] = df[score_cols].apply(pd.to_numeric, errors="coerce")
df["mean_score"] = df[score_cols].mean(axis=1)
df["std_score"] = df[score_cols].std(axis=1)
df["low_sat_flag"] = (df[score_cols] <= 3).any(axis=1)
df["serious_sat_flag"] = (df[score_cols] <= 2).any(axis=1)
df[["mean_score", "std_score", "low_sat_flag", "serious_sat_flag"]].head()왜 이렇게 했나?
평균이 높아도 특정 항목 하나의 낮은 점수는 충분히 가려질 수 있기 때문이다.
4. 세그먼트별로 묶어보니 차이가 보였다
이번 분석의 세그먼트 기준은 이용 목적이었다.
'이용 목적에 따라 만족도 구조는 달라지는가'를 핵심 질문으로 두었다.
코드 3. 세그먼트별 집계
segment_summary = (
df.groupby("cat_01")
.agg(
n=("response_id", "size"),
mean_score=("mean_score", "mean"),
mean_std=("std_score", "mean"),
low_sat_rate=("low_sat_flag", "mean"),
serious_sat_rate=("serious_sat_flag", "mean")
)
.reset_index()
)
segment_summary["low_sat_rate"] = (segment_summary["low_sat_rate"] * 100).round(1)
segment_summary["serious_sat_rate"] = (segment_summary["serious_sat_rate"] * 100).round(1)
segment_summary이 표 하나로 아래를 같이 볼 수 있다.
- 세그먼트별 평균
- 세그먼트별 편차
- 세그먼트별 저만족 비율
5. 가설 1 - 집단별 만족도 편차는 달랐을까
첫 번째 질문은 이거였다.
이용 목적에 따라 서비스 만족도 구조가 다른가?
세그먼트 간 평균 수준은 비슷했지만, 항목별 변동성 구조는 달랐고, 특히 운영 지원 항목에서 편차가 크게 나타났다. ANOVA 결과도 유의했다.
왜 ANOVA를 썼나
- 집단은 여러 개다
- 비교 대상은 연속형 점수다
즉, 여러 집단 평균 차이를 보는 문제라서 ANOVA가 맞다.
코드 4. ANOVA
from scipy.stats import f_oneway
anova_groups = [
group["sat_06"].dropna().values
for _, group in df.groupby("cat_01")
]
f_stat, p_value = f_oneway(*anova_groups)
print(f"F-statistic: {f_stat:.3f}")
print(f"p-value: {p_value:.4f}")| 세그먼트별 응답 비율 | 특정 만족도 조사 항목 점수 분포 |
 |
 |
6. 가설 2 - 저만족 비율은 집단마다 달랐을까
두 번째 질문은 평균보다 더 직접적이었다.
이용 목적에 따라 저만족 및 심각 저만족 비율 차이가 존재하는가?
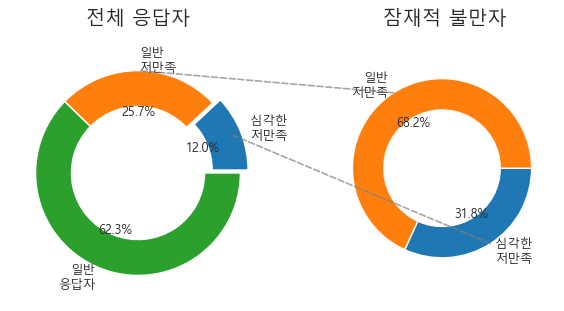
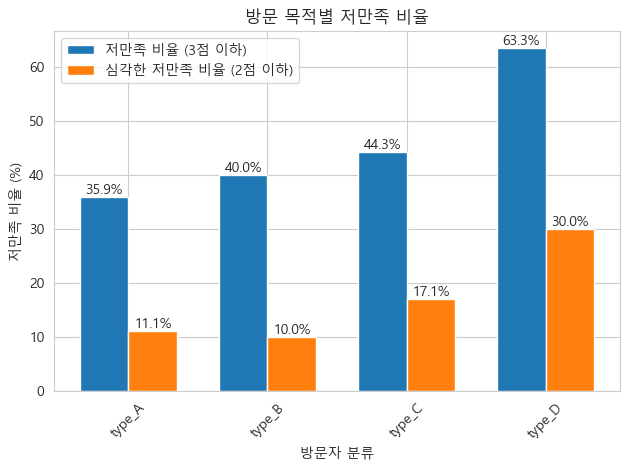
전체 응답자 기준 저만족 37%, 심각 저만족 12%가 나타났고, 세그먼트별로는 type_D 63%, type_A 34% 수준 차이가 확인됐다.
카이제곱 검정 결과도 유의했다.
왜 카이제곱을 썼나
- cat_01은 범주형
- low_sat_flag도 범주형
즉, 두 범주형 변수의 연관성을 보는 문제라서 카이제곱 검정이 맞다.
코드 5. 카이제곱 검정
from scipy.stats import chi2_contingency
import pandas as pd
contingency = pd.crosstab(df["cat_01"], df["low_sat_flag"])
chi2, p, dof, expected = chi2_contingency(contingency)
print(f"Chi-square statistic: {chi2:.3f}")
print(f"p-value: {p:.5f}")코드 6. 세그먼트별 저만족 비율
low_sat_by_segment = (
df.groupby("cat_01")["low_sat_flag"]
.mean()
.mul(100)
.round(1)
.sort_values(ascending=False)
)
low_sat_by_segment| 전체 응답자 중 잠재적 불만자 비율 | 방문 목적별 저만족 비율 |
 |
 |
7. 가설 3 - 낮은 만족도는 실제 불만 행동으로 이어졌을까
세 번째 질문은 정량과 정성을 연결하는 단계였다.
저만족 응답자의 주관식 의견에는 개선 요구 맥락이 포함되는가?
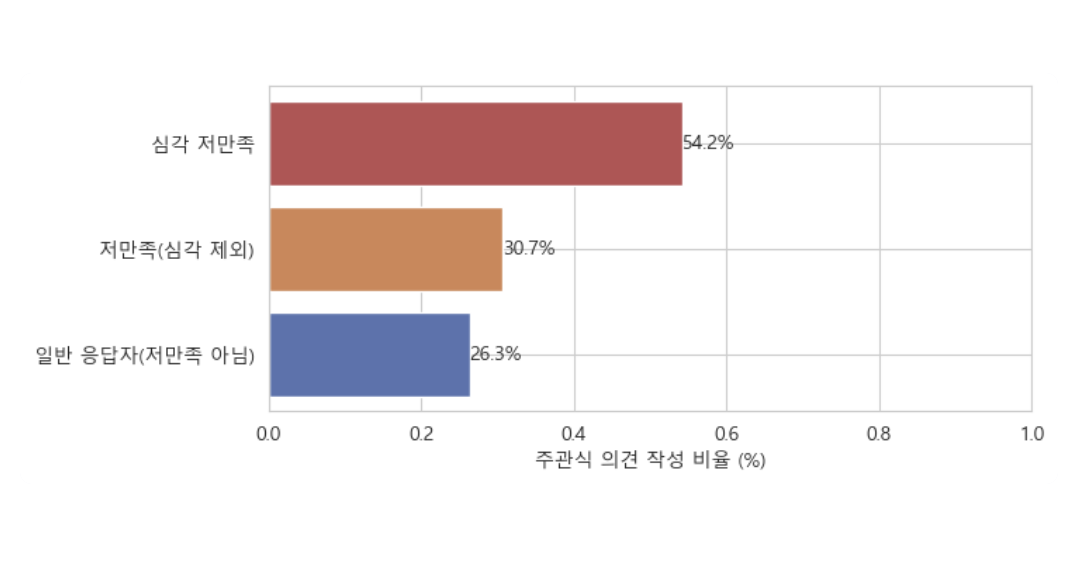
만족도 수준이 낮을수록 주관식 작성 비율과 불만 표현 비율이 함께 높아졌다.
왜 복잡한 NLP를 쓰지 않았나
이 단계에서 중요한 건 정교한 텍스트 모델보다
낮은 만족도가 실제 의견 작성 행동으로 이어지는지를 확인하는 것이었다.
코드 7. 주관식 작성 / 불만 표현 플래그
complaint_keywords = ["불편", "개선", "아쉽", "부족", "혼잡", "불만", "문의"]
df["text_response_flag"] = (
df["text_01"].fillna("").astype(str).str.strip() != ""
)
df["complaint_expr_flag"] = (
df["text_01"]
.fillna("")
.astype(str)
.str.contains("|".join(complaint_keywords), regex=True)
)코드 8. 만족도 그룹별 행동 비교
mask_general = (~df["low_sat_flag"]) & (~df["serious_sat_flag"])
mask_low_only = (df["low_sat_flag"]) & (~df["serious_sat_flag"])
mask_serious = df["serious_sat_flag"]
behavior_summary = pd.DataFrame({
"group": ["일반", "저만족", "심각 저만족"],
"text_response_rate": [
df.loc[mask_general, "text_response_flag"].mean(),
df.loc[mask_low_only, "text_response_flag"].mean(),
df.loc[mask_serious, "text_response_flag"].mean()
],
"complaint_expr_rate": [
df.loc[mask_general, "complaint_expr_flag"].mean(),
df.loc[mask_low_only, "complaint_expr_flag"].mean(),
df.loc[mask_serious, "complaint_expr_flag"].mean()
]
})
behavior_summary| 주관식 의견 작성 비율 | 주관식 의견 내 요구 / 불만 표현 비율 |
 |
 |
8. 정리
이번 분석에서 확인한 건 명확했다.
- 평균은 비슷해도 집단별 경험 구조는 달랐다.
- 저만족 비율은 세그먼트마다 다르게 나타났다.
- 낮은 만족도는 실제 불만 행동으로 이어졌다.
전체 평균은 높지만, 집단별 경험 차이가 존재했고, 운영 리스크는 평균보다 낮은 점수와 편차가 큰 구간에서 더 잘 드러난다.
이번 분석에서 확인한 것
- 평균 만족도만으로는 운영 리스크를 보기 어려웠다.
- 세그먼트와 저만족 지표를 함께 봐야 차이가 드러났다.
- 주관식 행동 신호까지 연결해야 실제 개선 포인트가 보였다.
9. 마무리
이번 작업은 “평균이 높다”는 결과를 다시 확인하는 분석이 아니었다.
오히려 그 평균 뒤에 가려진 구조를 지표와 코드로 꺼내 본 과정이었다.
다음 글에서는 여기서 한 걸음 더 나아가,
이 결과를 실제 운영 개선 과제와 KPI 설계로 어떻게 연결했는지 정리할 예정이다.
Education-Data-Analysis/01-training-center-survey-analysis at main · devellybutton/Education-Data-Analysis
설문 데이터를 분석해 핵심 지표를 도출하고, 가설 및 통계 검증을 통해 의사결정을 지원한 프로젝트입니다. - devellybutton/Education-Data-Analysis
github.com
https://programming-bellybutton.tistory.com/260
연말 설문 분석 2편: 주관식 불만 분류부터 KPI 설계까지: 운영 개선 구조 만들기
설문 분석에서 끝내지 않고 운영 개선으로 연결한 방법리스크 지표와 실행 우선순위를 만드는 과정지난 글에서는 평균 만족도 뒤에 숨어 있던 저만족 신호를 찾는 과정을 정리했다. https://program
programming-bellybutton.tistory.com
'실전 기술 활용 > 데이터 분석' 카테고리의 다른 글
| Python으로 교육 수요 설문 분석하기 (1) 중요도·실행도·GAP 계산 (0) | 2026.06.14 |
|---|---|
| 연말 설문 분석 2편: 주관식 불만 분류부터 KPI 설계까지: 운영 개선 구조 만들기 (0) | 2026.06.14 |
| 교육 효과 분석 2편: 분석 결과를 Streamlit 대시보드로 만들기 (0) | 2026.06.03 |
| 교육 효과 분석 1편: 대응표본 t-test로 검증한 교육 전후 변화 (0) | 2026.06.03 |
| 추론 통계 기본 개념 정리 - 표준편차, 신뢰구간, p-value까지 (0) | 2026.06.03 |



