
- 분류 전체보기 (254)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 개발자취업
- Python
- 프로그래머스
- mongoDB
- node.js
- nestjs
- TiL
- 엘리스sw트랙
- 중간이들
- 파이썬
- 코드잇
- 코딩테스트준비
- 데이터베이스시스템
- JavaScript
- Git
- CSS
- 오픈소스기반데이터분석
- 방송대컴퓨터과학과
- 데이터분석
- 꿀단집
- Azure
- 99클럽
- 코딩테스트
- 방송대
- aws
- 항해99
- HTML
- 클라우드컴퓨팅
- 유노코딩
- 파이썬프로그래밍기초
- Today
- Total
배꼽파, 오늘도 배꼽 대신 데이터를 판다
연말 설문 분석 2편: 주관식 불만 분류부터 KPI 설계까지: 운영 개선 구조 만들기 본문

설문 분석에서 끝내지 않고 운영 개선으로 연결한 방법
리스크 지표와 실행 우선순위를 만드는 과정
지난 글에서는 평균 만족도 뒤에 숨어 있던 저만족 신호를 찾는 과정을 정리했다.
https://programming-bellybutton.tistory.com/259
연말 설문 분석 1편: Python과 Pandas로 평균 만족도 뒤의 저만족 신호 분석하기
평균 만족도가 높아도 문제는 숨어 있을 수 있다설문 평균 뒤에 가려진 저만족 신호를 코드로 확인한 과정만족도 설문은 보통 평균부터 본다.문제는 평균이 높아도, 일부 집단의 반복적 불편은
programming-bellybutton.tistory.com
이번 글에서는 그 결과를 실제 운영 개선 구조로 어떻게 바꿨는지 정리한다.
핵심은 3가지였다.
- 주관식 불만을 실행 가능한 카테고리로 묶기
- 비용-효과 기준으로 우선순위 나누기
- 평균 중심 KPI를 리스크 중심 KPI로 바꾸기
이번 글에서 구현한 것
- 주관식 의견을 규칙 기반으로 분류했다.
- 카테고리별 빈도와 우선순위를 정리했다.
- 운영용 KPI 테이블을 별도로 만들었다.
- 다음 설문 설계 기준까지 정리했다.
1. 분석 결과를 바로 실행으로 옮기기 어려웠다
1편에서 확인한 결과는 분명했다.
- 특정 세그먼트의 저만족 비율이 높았다
- 낮은 만족도는 주관식 불만으로 이어졌다
- 평균만으로는 운영 리스크가 잘 보이지 않았다
문제는 이걸 바로 액션으로 옮기기 어렵다는 점이었다.
그래서 먼저 주관식 의견을 실행 가능한 문제 단위로 다시 묶는 작업이 필요했다.
| 분석 결과 | 어려운 점 | 다음 단계 |
| 저만족 비율이 높음 | 무엇부터 바꿔야 할지 안 보임 | 문제 유형 분류 |
| 주관식 불만 다수 | 해석이 주관적으로 흐를 수 있음 | 카테고리화 |
| 평균 외 리스크 존재 | 계속 추적할 기준 필요 | KPI 재설계 |
2. 주관식 의견을 먼저 카테고리화했다
처음부터 복잡한 NLP를 쓰진 않았다.
초기 목적은 정교한 분류보다 운영에서 바로 쓸 수 있는 묶음을 만드는 것이었기 때문이다.
코드 1. 규칙 기반 카테고리 분류
import re
import pandas as pd
category_rules = {
"운영 안내": ["안내", "헷갈", "설명", "정보", "공지"],
"서비스 대응": ["응대", "친절", "불친절", "대응", "태도"],
"프로세스": ["절차", "과정", "복잡", "번거", "대기"],
"환경": ["공간", "환경", "자리", "소음", "혼잡"],
"운영 지원": ["지원", "도움", "문의", "연결", "처리"]
}
def classify_comment(text: str) -> str:
if pd.isna(text) or str(text).strip() == "":
return "미작성"
text = str(text)
matched = []
for category, keywords in category_rules.items():
if any(re.search(keyword, text) for keyword in keywords):
matched.append(category)
if not matched:
return "기타"
if len(matched) == 1:
return matched[0]
return ", ".join(matched)
df["issue_category"] = df["text_01"].apply(classify_comment)
df[["text_01", "issue_category"]].head(10)왜 이렇게 했나
- 빠르게 적용 가능
- 해석이 쉬움
- 회의에서 설명하기 좋음
- 기준 수정이 쉬움
3. 어떤 문제가 반복되는지 먼저 봤다
카테고리를 나눈 뒤에는 빈도를 봤다.
실무에서는 한두 개 강한 의견보다, 반복적으로 나오는 문제가 더 중요하다.
코드 2. 카테고리별 빈도 집계
issue_freq = (
df.loc[df["issue_category"] != "미작성", "issue_category"]
.value_counts()
.reset_index()
)
issue_freq.columns = ["issue_category", "count"]
issue_freq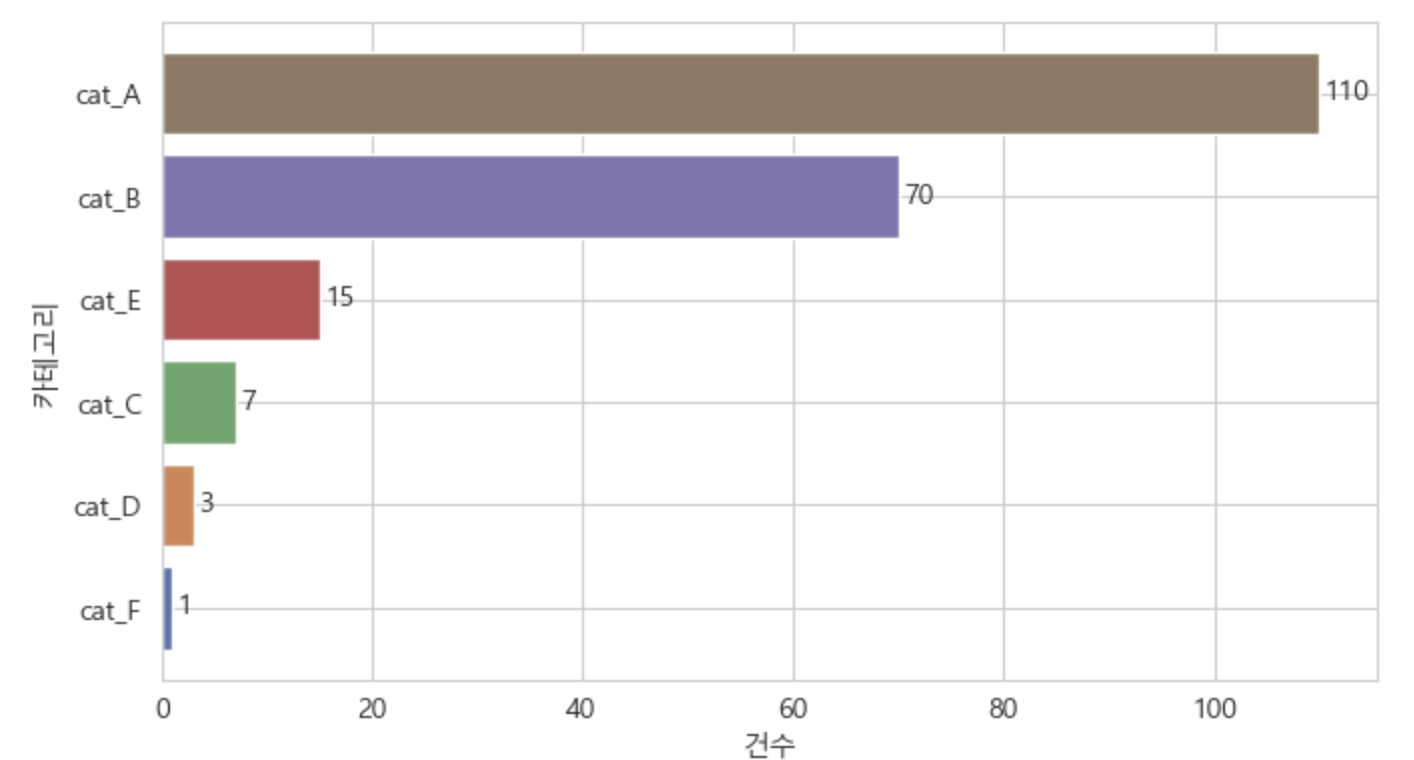
4. 많이 나온 문제와 먼저 고칠 문제는 달랐다
빈도가 높다고 바로 우선순위 1순위는 아니다.
주관식 불만 응답을 비용 vs 효과 기준으로 분류해 실행 우선순위를 설정했다.
저비용·고효과는 즉시 개선, 고비용·고효과는 투자 검토, 구조적 제약은 장기 검토로 구분했다.

비용-효과 기준
| 구분 | 의미 | 대응 방식 |
| 저비용 / 고효과 | 빠르게 바꿀 수 있고 효과 큼 | 즉시 개선 |
| 고비용 / 고효과 | 중요하지만 자원 필요 | 투자 검토 |
| 저비용 / 저효과 | 체감 작음 | 보류 가능 |
| 고비용 / 저효과 | 당장 우선순위 낮음 | 장기 검토 |
코드 3. 카테고리별 우선순위 기준 붙이기
priority_map = {
"운영 안내": {"cost": "low", "impact": "high"},
"서비스 대응": {"cost": "medium", "impact": "high"},
"프로세스": {"cost": "medium", "impact": "high"},
"환경": {"cost": "high", "impact": "medium"},
"운영 지원": {"cost": "high", "impact": "high"},
"기타": {"cost": "unknown", "impact": "unknown"}
}
issue_freq["cost"] = issue_freq["issue_category"].map(
lambda x: priority_map.get(x, {}).get("cost", "unknown")
)
issue_freq["impact"] = issue_freq["issue_category"].map(
lambda x: priority_map.get(x, {}).get("impact", "unknown")
)
issue_freq5. KPI도 평균 중심에서 리스크 중심으로 바꿨다
분석을 한 번 하고 끝낼 게 아니라면,
이후에도 같은 문제를 지속적으로 추적할 지표가 필요하다.
원본 문서에서는 평균만 보면 놓치는 것들이 있기 때문에, 리스크 지표를 추가해 잠재 불만을 조기에 잡는 구조로 확장했다.
종합 KPI 외에 저만족 비율, 심각 저만족 비율, 항목별 표준편차, 주관식 작성률, 불만 표현 비율을 함께 관리 대상으로 뒀다.
| 구분 | 기존 | 개선 후 |
| 종합 지표 | 평균 만족도 | 평균 만족도 |
| 리스크 지표 | 거의 없음 | 저만족 비율, 심각 저만족 비율 |
| 안정성 지표 | 없음 | 항목별 표준편차 |
| 행동 지표 | 주관식 참고 | 작성률, 불만 표현 비율 |
코드 4. 운영용 KPI 테이블
kpi_summary = {
"avg_mean_score": round(df["mean_score"].mean(), 2),
"low_sat_rate": round(df["low_sat_flag"].mean() * 100, 1),
"serious_sat_rate": round(df["serious_sat_flag"].mean() * 100, 1),
"avg_std_score": round(df["std_score"].mean(), 2),
"text_response_rate": round(df["text_response_flag"].mean() * 100, 1),
"complaint_expr_rate": round(df["complaint_expr_flag"].mean() * 100, 1),
}
kpi_summary왜 바꿨나
- 평균만 보면 숨은 리스크가 안 보임
- 낮은 점수 구간을 별도로 추적해야 함
- 주관식 행동도 같이 봐야 체감 개선을 볼 수 있음
6. 결국 다음 설문도 다시 설계해야 했다
좋은 분석은 좋은 데이터에서 나온다.
그래서 현재 결과 해석으로 끝내지 않고, 다음 설문 구조도 손봤다.
설문 설계 구조 고도화로 세그먼트별 목표 응답 수 설정, 방문 이력 변수 추가, 문항 재설계, KPI 먼저 정의 후 설계하는 방식 전환 등이 필요했다.
바꾼 방향
- 세그먼트별 목표 응답 수 설정
- 방문 이력 변수 추가
- 중복 문항 정리
- KPI 먼저 정의하고 설문 설계
코드 5. 다음 설문 스키마 정리
survey_schema = {
"segment_fields": ["cat_01", "visit_count"],
"score_fields": ["sat_01", "sat_02", "sat_03", "sat_04", "sat_05", "sat_06"],
"text_fields": ["text_01"],
"target_kpis": [
"avg_mean_score",
"low_sat_rate",
"serious_sat_rate",
"avg_std_score",
"text_response_rate",
"complaint_expr_rate"
]
}
survey_schema7. 정리
이번 작업에서 중요했던 건 단순히 불만을 찾는 게 아니었다.
- 불만을 카테고리로 묶고
- 우선순위를 정하고
- KPI로 계속 추적하고
- 다음 설문 설계까지 바꾸는 것
즉, 분석 결과를 운영 의사결정 구조로 바꾸는 과정이 핵심이었다. 원본 문서의 핵심 요약도 단순 만족도 평균을 넘어 리스크 지표로 잠재 불만을 조기 탐지하고, 비용-효과 매트릭스로 실행 우선순위를 잡고, 분석 결과를 다음 설문 설계에 반영했다는 점에 있다.
이번 작업에서 얻은 것
- 분석 결과를 실행 우선순위표로 바꿨다.
- 평균 외 리스크 KPI를 운영 관리 지표로 추가했다.
- 다음 설문은 분석하기 쉬운 구조로 다시 설계했다.
8. 마무리
설문 데이터 분석은 “평균이 몇 점이냐”를 정리하는 데서 끝나면 아쉽다.
실무에서 더 중요한 것은 어떤 문제가 반복되는지, 무엇부터 바꿔야 하는지, 이후에 뭘 계속 봐야 하는지를 정하는 일이다.
Education-Data-Analysis/01-training-center-survey-analysis at main · devellybutton/Education-Data-Analysis
설문 데이터를 분석해 핵심 지표를 도출하고, 가설 및 통계 검증을 통해 의사결정을 지원한 프로젝트입니다. - devellybutton/Education-Data-Analysis
github.com
'실전 기술 활용 > 데이터 분석' 카테고리의 다른 글
| Python으로 교육 수요 설문 분석하기 (2) 시각화와 우선순위 분류 (0) | 2026.06.14 |
|---|---|
| Python으로 교육 수요 설문 분석하기 (1) 중요도·실행도·GAP 계산 (0) | 2026.06.14 |
| 연말 설문 분석 1편: Python과 Pandas로 평균 만족도 뒤의 저만족 신호 분석하기 (0) | 2026.06.14 |
| 교육 효과 분석 2편: 분석 결과를 Streamlit 대시보드로 만들기 (0) | 2026.06.03 |
| 교육 효과 분석 1편: 대응표본 t-test로 검증한 교육 전후 변화 (0) | 2026.06.03 |



