
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 파이썬
- 99클럽
- 유노코딩
- 클라우드컴퓨팅
- aws
- 코딩테스트준비
- 데이터베이스시스템
- JavaScript
- HTML
- 중간이들
- 개발자취업
- 파이썬프로그래밍기초
- Git
- mongoDB
- 방송대
- 꿀단집
- Azure
- 코딩테스트
- 방송대컴퓨터과학과
- 데이터분석
- 엘리스sw트랙
- 프로그래머스
- 오픈소스기반데이터분석
- nestjs
- Python
- TiL
- 항해99
- 코드잇
- CSS
- node.js
- Today
- Total
배꼽파, 오늘도 배꼽 대신 데이터를 판다
교육 효과 분석 1편: 대응표본 t-test로 검증한 교육 전후 변화 본문

교육 만족도만으로는 부족했다
사전·사후 설문 데이터로 교육 효과를 검증한 과정
만족도 평균만 보던 교육 운영 데이터를,
사전·사후 설문 매칭과 통계 검증으로 다시 해석해 “실제로 교육 효과가 있었는가”를 확인한 프로젝트다.
이 사례는 실제 분석 경험을 바탕으로 재구성했으며,
일부 수치는 가상 데이터로 단순화했지만 문제 정의와 분석 구조는 동일하다.
들어가며
교육 운영 업무를 하다 보면 자주 듣는 질문이 있다.
“그래서 이 교육, 실제로 효과가 있었나요?”
겉으로 보기에는 단순한 질문 같지만, 현업에서는 의외로 명확하게 답하기 어렵다.
대부분의 교육에서는 만족도 조사 결과를 확인하지만, 만족도가 높다고 해서 실제로 학습자의 이해도나 역량이 향상되었다고 단정할 수는 없다.
내가 진행했던 프로젝트도 이 지점에서 시작됐다. 기존에는 교육 후 만족도 평균만 확인하고 있었고, 교육이 실제 역량 향상에 기여했는지를 정량적으로 검증하는 구조는 없었다.
그래서 동일 참여자의 사전·사후 설문을 연결해 교육 효과를 통계적으로 검증하는 방식으로 분석을 다시 설계했다.

이 글에서 다루는 내용
이번 글에서는 다음 질문에 답하려고 한다.
- 만족도 평균만으로는 왜 부족했는가
- 사전·사후 설문 데이터는 어떤 문제를 안고 있었는가
- 어떤 가설을 세우고, 어떤 방식으로 검증했는가
- 분석 결과를 통해 어떤 인사이트를 얻었는가
대시보드 구현과 활용은 2편에서 별도로 다룰 예정이다. 이번 1편은 문제 정의부터 분석 결과 해석까지에 집중한다. README에서도 이 프로젝트는 프로젝트 개요 → 문제 정의 → 가설 설정 → 데이터 및 지표 정의 → 분석/검증 → 인사이트 해석 순으로 정리되어 있다.
1. 문제는 “만족도”가 아니라 “효과 검증”이었다
교육 운영 현장에서는 회차별 만족도 평균을 확인하는 경우가 많다. 이 방식은 빠르고 직관적이지만, 운영 개선에는 한계가 있다.
만족도 평균은 “좋았다 / 나빴다”에 대한 반응은 보여주지만, 교육 이전과 이후를 비교해 실제로 무엇이 달라졌는지는 보여주지 않기 때문이다.
이번 프로젝트의 출발점도 같았다. 교육 센터는 매 회차 교육을 운영하고 있었지만, 교육의 실제 효과를 정량적으로 입증할 수 있는 지표가 부족했다. 그래서 단순 만족도 평균이 아니라, 동일 참여자의 교육 전·후 점수 차이를 비교해 교육 효과의 존재 여부와 크기를 함께 검증하는 방향으로 분석 목표를 잡았다.
2. 데이터는 생각보다 깔끔하지 않았다
분석 대상 데이터는 1개월 동안 진행된 오프라인 교육 참여자 설문 100건이며, 총 5회차 교육으로 구성되어 있었다. 데이터에는 동일 참여자의 사전·사후 설문, 리커트 5점 척도 기반 역량 문항, 그리고 직무·엑셀 사용 경험·회차 같은 보조 변수가 포함되어 있었다.
하지만 실제 분석을 시작해보면 데이터는 바로 쓸 수 있는 상태가 아니었다. 운영 현장 데이터답게 몇 가지 현실적인 문제가 있었다.
- 회차, 날짜, 직종 등의 오기재
- 교육 전 또는 교육 후 설문 미완료로 인한 결측
- 동일 응답자의 중복 제출
- 특정 회차의 낮은 응답률
즉, 이 프로젝트는 “분석 기법을 고르는 문제” 이전에, 동일 집단을 제대로 통제할 수 있는가가 더 중요한 문제였다. 사전·사후 설문을 같은 사람 기준으로 정확히 연결하지 못하면, 전후 비교 자체가 흔들리기 때문이다.
3. 그래서 먼저 한 일: 같은 사람끼리 비교할 수 있게 만들기
이번 분석에서는 사전·사후 응답을 단순 집계하지 않고, 동일 참여자 기준으로 매칭한 뒤 비교했다. 이를 위해 익명 ID 형태의 고유 식별 키를 부여하고, 사전·사후 응답을 연결한 뒤 불일치 데이터는 제거했다. 최종적으로는 사전·사후 모두 응답한 참여자만 분석 대상에 포함했다.
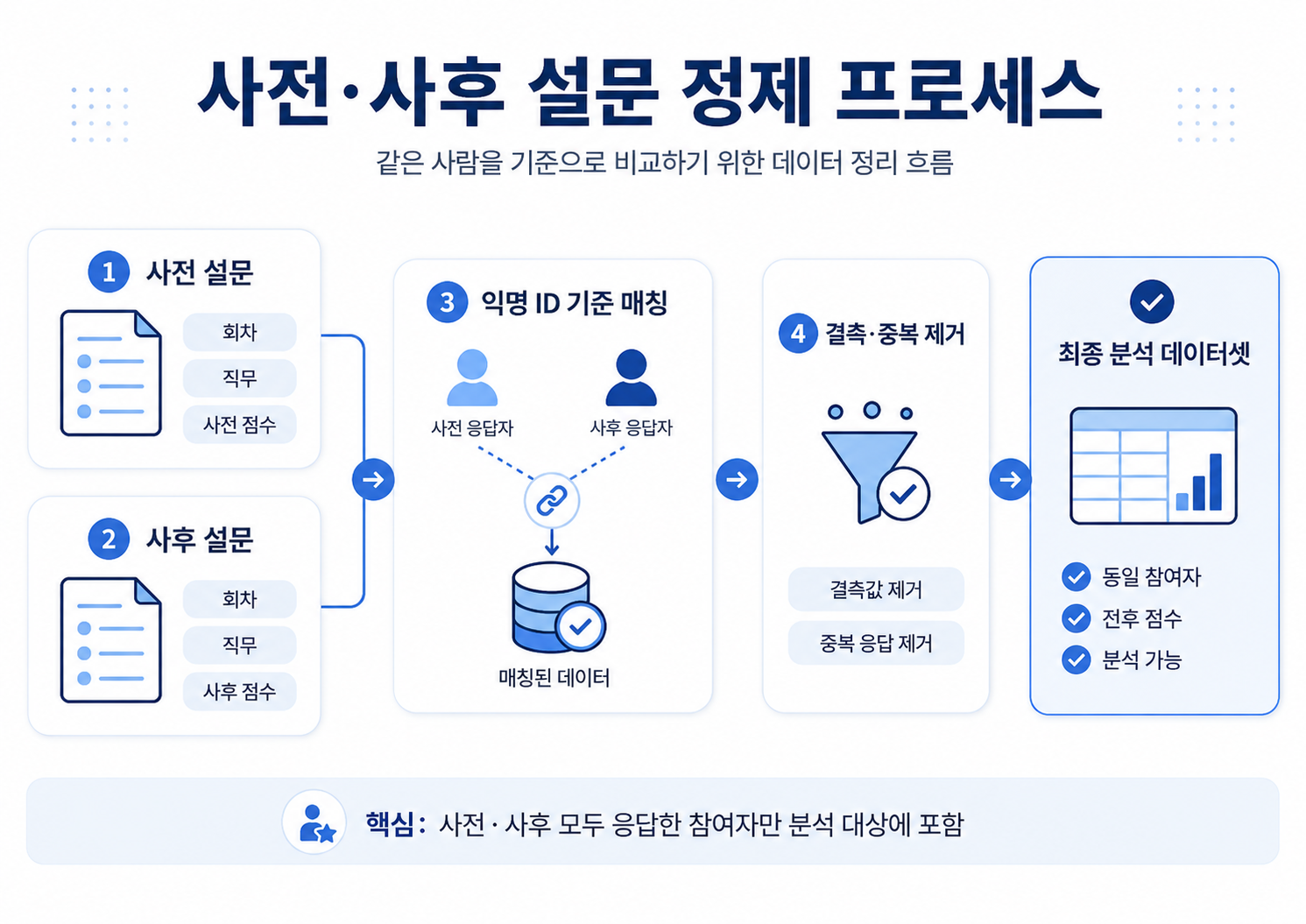
이 단계가 중요한 이유는 분명하다.
사전 평균과 사후 평균을 각각 따로 계산하는 것은 쉽지만, 그렇게 하면 “교육 전 점수가 낮았던 사람이 교육 후 얼마나 달라졌는가”를 같은 기준으로 볼 수 없다. 반면 동일 응답자를 기준으로 매칭하면, 전후 변화량 자체를 직접 계산할 수 있고 그 차이가 우연인지 아닌지도 검정할 수 있다. 이 프로젝트에서 평균 향상폭, 대응표본 t-test, Wilcoxon 검정, 신뢰구간, 효과 크기까지 모두 볼 수 있었던 이유도 이 통제 과정을 먼저 거쳤기 때문이다.
4. 이번 분석에서 세운 가설
분석은 크게 네 가지 질문으로 시작했다.
| 가설 | 질문 | 목적 |
| H1 | 교육 후 평균 점수는 교육 전보다 유의하게 높은가 | 전체 효과 검증 |
| H2 | 그 차이는 실질적으로도 의미 있는 수준인가 | 효과 크기 확인 |
| H3 | 직무·회차·사용경력에 따라 향상폭 차이가 있는가 | 집단 차이 탐색 |
| H4 | 초기 점수와 배경 변수는 향상폭에 영향을 주는가 | 예측 요인 탐색 |
실제 README에서도 같은 구조로 가설을 정리했다. 단순히 “평균이 올랐는가”만 보는 것이 아니라, 효과가 얼마나 큰지, 어떤 집단에서 더 크게 나타나는지, 초기 상태가 결과에 어떤 영향을 주는지까지 함께 보도록 설계했다.
5. 어떤 지표로 검증했는가
이번 프로젝트에서 본 핵심 지표는 아래와 같다.
- 사전 평균 점수
- 사후 평균 점수
- 평균 향상폭(post - pre)
- 대응표본 t-test
- Wilcoxon 검정
- 95% 신뢰구간
- Cohen’s d
- 회차별/직종별/엑셀 사용경력별 향상폭
즉, 하나의 숫자로 끝내지 않고 평균 변화, 통계적 유의성, 효과 크기, 세그먼트별 차이를 함께 보는 구조로 가져갔다. 이 조합은 실무에서 특히 유용하다. 평균만 보면 “조금 오른 것 같은데?” 수준에서 끝날 수 있고, p-value만 보면 “유의하긴 한데 그래서 얼마나 중요한데?”라는 질문이 남기 때문이다. 반대로 효과 크기와 세그먼트 결과까지 함께 보면, 실제 운영 액션으로 이어질 가능성이 커진다.
6. 분석 결과: 교육 효과는 실제로 존재했다
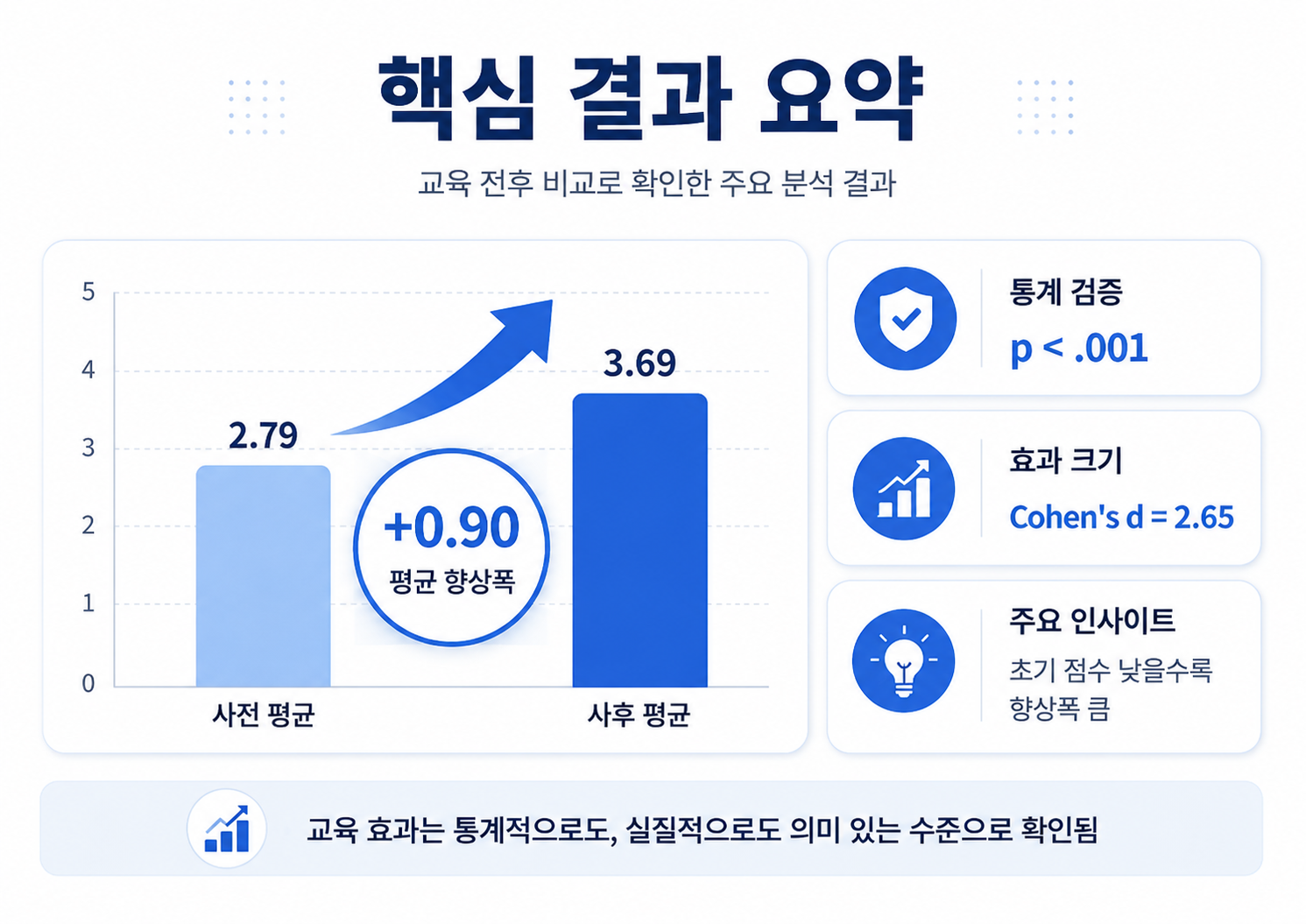
가장 먼저 확인한 것은 전체 효과였다. 대응표본 t-test와 Wilcoxon 검정 모두 유의하게 나왔고, 95% 신뢰구간도 0을 넘는 구간으로 형성되었다. README 기준으로는 대응표본 t-test와 Wilcoxon 모두 p < .001, 평균 차이에 대한 95% 신뢰구간은 0.826 ~ 0.972였다. 이는 교육 후 평균 점수가 교육 전보다 통계적으로 유의하게 상승했음을 보여준다.
효과 크기도 충분히 컸다. Cohen’s d는 2.65로 정리되어 있었는데, 일반적인 기준에서 0.8 이상이면 큰 효과로 보는 점을 감안하면 상당히 큰 수준이다. 즉, 이번 결과는 “유의하긴 하지만 실제 차이는 작다”에 가까운 결과가 아니라, 통계적으로도 유의하고 실질적으로도 의미 있는 상승에 가깝다.
7. 평균만 보면 놓치는 것들: 어떤 집단에서 더 많이 올랐는가
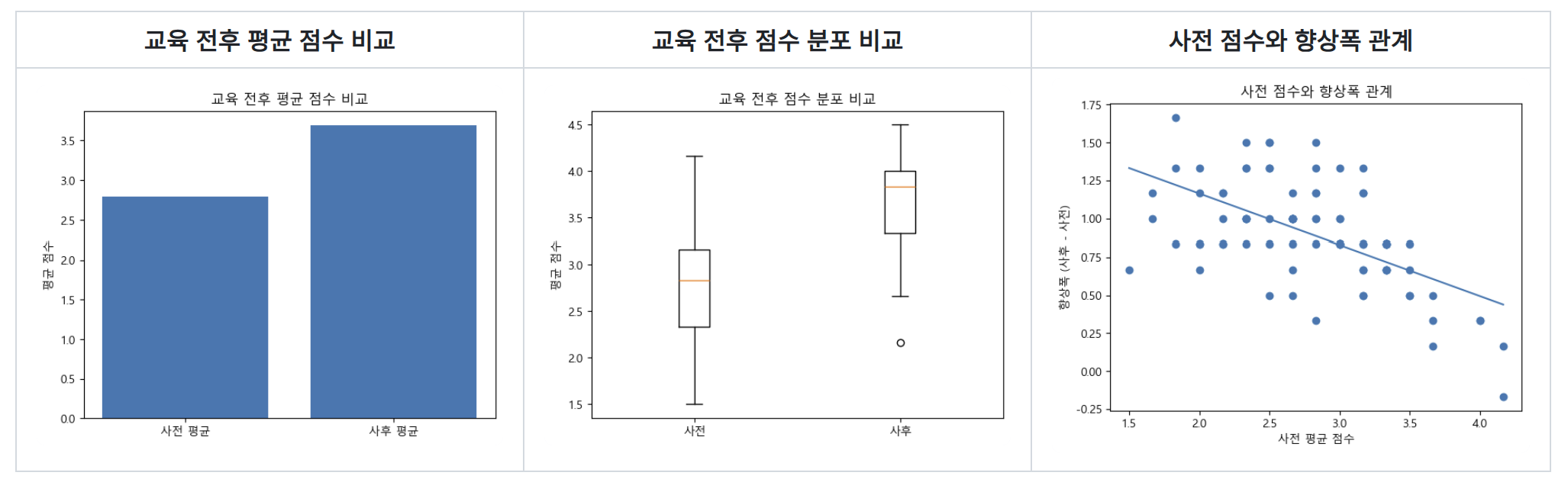
전체 평균 상승도 중요하지만, 운영 관점에서는 누가 더 많이 좋아졌는가가 더 중요할 때가 많다.
이번 프로젝트에서는 직무, 회차, 엑셀 사용경력별 차이도 함께 확인했다.
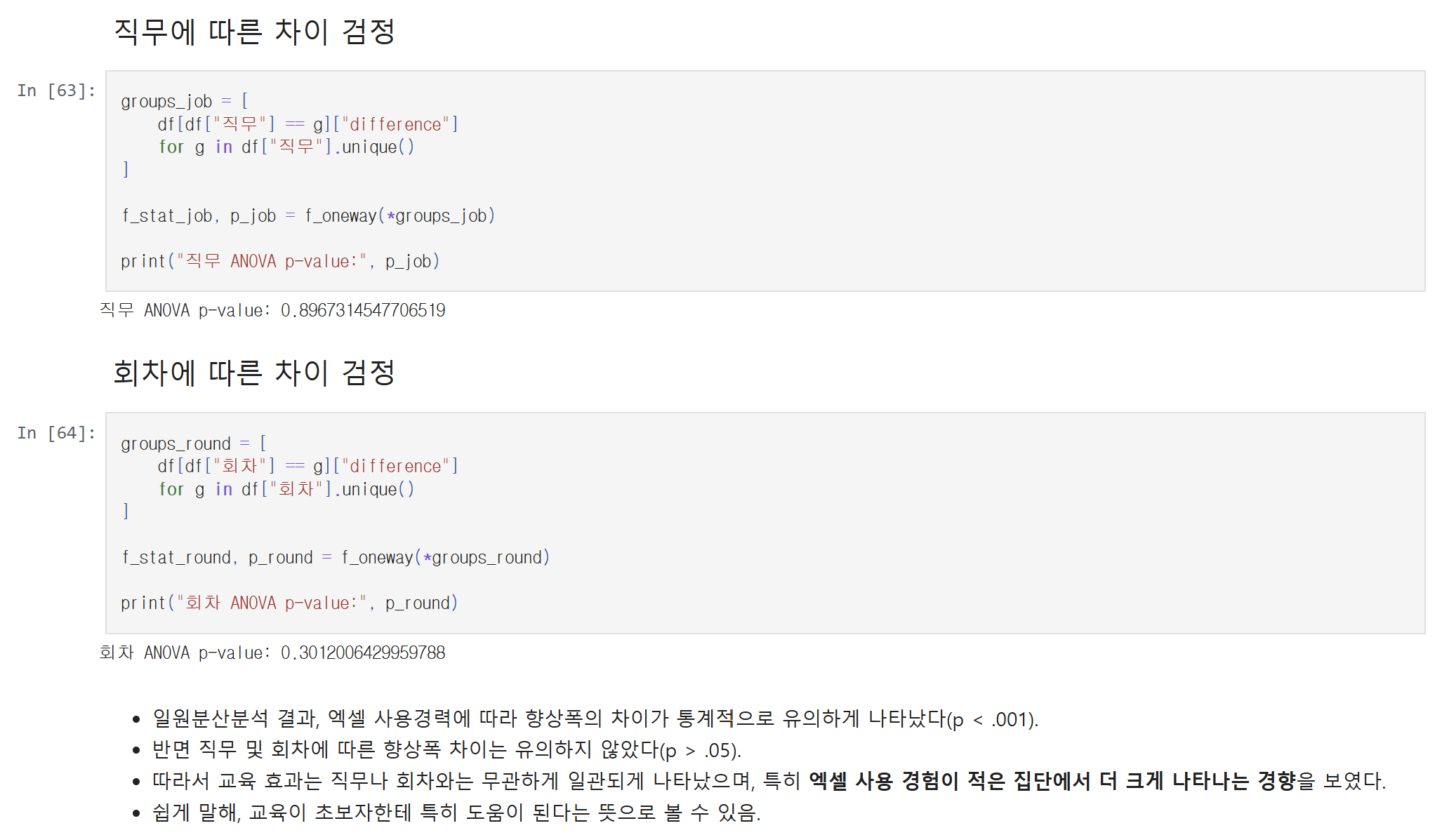
그 결과, 회차와 직무에 따른 향상폭 차이는 유의하지 않았지만, 엑셀 사용경력에 따라서는 향상폭 차이가 유의하게 나타났다. 정리된 결과에 따르면 엑셀 사용경력 ANOVA는 p < .001, 반면 직무 ANOVA는 p = 0.896, 회차 ANOVA는 p = 0.301이었다. 해석하면, 교육 운영 품질은 회차 간 큰 차이 없이 비교적 안정적이었고, 직무에 따라서도 뚜렷한 차이는 없었지만, 초급자일수록 교육 효과가 더 크게 나타난 것이다.
예측 요인 분석도 같은 방향을 보여줬다. OLS 회귀 결과에서 초기 점수 계수는 -0.335, R²는 0.341로 정리되어 있었다. 즉, 교육 전 점수가 낮을수록 향상폭은 더 크게 나타나는 경향이 있었다. 이 결과는 직관적으로도 이해하기 쉽다. 이미 높은 수준에 있는 학습자는 상승 여지가 상대적으로 작고, 반대로 기초 수준 학습자는 같은 교육에서도 체감 향상폭이 더 크게 나타날 수 있기 때문이다.
8. 이 결과가 운영에 주는 의미
이 분석의 가치는 “교육 효과가 있었다”는 결론 하나에만 있지 않다.
오히려 더 중요한 것은, 이 결과를 통해 운영자가 어떤 결정을 할 수 있게 되었는가다.
README에서는 이 결과를 바탕으로 다음과 같은 액션을 제안했다.
- 초급자 중심 마케팅 확대
- 사전 진단 점수 기반 수준별 반 배치 검토
- 중·고급자 대상 심화 과정 설계
- 회차별 운영 품질 모니터링 체계 유지
특히 인상적이었던 점은, 분석이 단순 보고서에서 끝나지 않고 누구를 주요 타깃으로 삼아야 하는가, 어떤 과정이 추가로 필요할까, 운영 품질은 안정적인가 같은 실제 의사결정 질문으로 이어졌다는 것이다. 데이터 분석이 실무에서 의미를 가지려면 결국 이 단계까지 가야 한다고 생각한다.
9. 이번 프로젝트에서 배운 점
이번 프로젝트를 하면서 다시 확인한 것은, 현업 데이터 분석은 “모델을 얼마나 복잡하게 쓰는가”보다 질문을 얼마나 정확히 정의하는가가 더 중요하다는 점이었다.
처음부터 필요한 것은 화려한 대시보드나 복잡한 예측 모델이 아니었다.
먼저 해야 했던 일은 아래 세 가지였다.
- 지금 보고 있는 지표가 정말 문제를 설명하는가
- 같은 사람끼리 비교할 수 있도록 데이터를 정리했는가
- 결과를 운영 의사결정으로 연결할 수 있는가
이번 사례는 이 세 가지를 비교적 잘 보여준다. 만족도 평균만으로는 부족했던 문제를, 동일 집단 기준의 사전·사후 비교와 통계 검증으로 다시 해석했고, 그 결과를 교육 운영 액션으로 연결할 수 있었다.
마무리
이번 글에서는 교육 효과 분석 프로젝트의 문제 정의, 데이터 통제, 가설 설정, 통계 검증 결과를 중심으로 정리했다. 핵심은 단순 만족도 집계에서 끝나지 않고, 사전·사후 설문을 같은 사람 기준으로 연결해 실제 변화량을 검증했다는 점이다. 그리고 그 결과, 교육은 전반적으로 유의한 효과를 보였고 특히 초급자 집단에서 더 큰 향상폭이 나타났다.
다음 글에서는 이 분석 결과를 바탕으로 어떤 KPI를 설계했고, 이를 어떻게 Streamlit 대시보드로 시각화했는지 정리해보려고 한다. 실제로는 회차, 직무, 엑셀 사용경력 필터를 두고 응답자 수·사전 평균·사후 평균·평균 향상폭을 한 화면에서 볼 수 있도록 구성했다.
Education-Data-Analysis/03-training-effectiveness-evaluation at main · devellybutton/Education-Data-Analysis
설문 데이터를 분석해 핵심 지표를 도출하고, 가설 및 통계 검증을 통해 의사결정을 지원한 프로젝트입니다. - devellybutton/Education-Data-Analysis
github.com
'실전 기술 활용 > 데이터 분석' 카테고리의 다른 글
| 교육 효과 분석 2편: 분석 결과를 Streamlit 대시보드로 만들기 (0) | 2026.06.03 |
|---|---|
| 추론 통계 기본 개념 정리 - 표준편차, 신뢰구간, p-value까지 (0) | 2026.06.03 |
| 기술통계 정리 - 수식과 그래프로 이해하기 (0) | 2026.06.03 |


