
- 분류 전체보기 (254)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 프로그래머스
- 클라우드컴퓨팅
- 파이썬
- CSS
- 방송대컴퓨터과학과
- aws
- 엘리스sw트랙
- 데이터분석
- 코딩테스트
- JavaScript
- 오픈소스기반데이터분석
- mongoDB
- 코딩테스트준비
- 중간이들
- 파이썬프로그래밍기초
- TiL
- Git
- Python
- 꿀단집
- 코드잇
- nestjs
- 데이터베이스시스템
- 개발자취업
- HTML
- 방송대
- node.js
- 99클럽
- 유노코딩
- 항해99
- Azure
- Today
- Total
배꼽파, 오늘도 배꼽 대신 데이터를 판다
Python으로 교육 수요 설문 분석하기 (1) 중요도·실행도·GAP 계산 본문

기업 교육 과정 우선순위는 어떻게 정할까?
Python으로 중요도–실행도 GAP 계산해 공통 교육과정 개설 기준 만들기
한 줄 요약
기업 대상 교육을 운영하다 보면 “어떤 과정을 먼저 열어야 하는가”라는 질문과 마주하게 된다.
이번 글에서는 제조 기업 HRD 담당자 설문 응답 60건을 바탕으로, 중요도·실행도·GAP을 계산해 공통 교육과정 우선순위를 정한 과정을 Python 중심으로 정리한다.
들어가며
기업 대상 교육을 운영하다 보면 비슷한 고민이 반복된다.
- 어떤 교육 과정을 우선적으로 개설해야 할까?
- 현장에서 필요하다고 말하는 과정이 정말 우선순위가 높은 걸까?
- 중요하다고 느끼는 영역과 실제로 부족한 영역은 같은 걸까?
당시에도 비슷한 상황이었다.
스마트팩토리 전환을 추진하는 제조 기업을 대상으로 맞춤형 교육을 운영하던 중, 공통 교육과정을 정리하고 우선순위를 도출해야 했다. 하지만 이를 판단할 정량 기준은 없는 상태였다. 그래서 기업 HRD 담당자 설문 데이터를 기반으로 중요도(Importance), 실행도(Performance), 그리고 GAP(중요도-실행도) 을 계산해 우선순위를 구조화했다. 분석 대상은 제조 기업 HRD 담당자 설문 응답 60건이었다.
이번 글에서는 결과 해석보다 먼저,
이 문제를 어떤 데이터 구조로 보고, Python으로 어떻게 계산했는지를 중심으로 정리해보려 한다.
문제 정의
이번 분석에서 답하고 싶었던 질문은 아래와 같았다.
| 질문 | 설명 |
| 어떤 교육 과정을 우선적으로 개설해야 하는가 | 공통 교육과정 개설 우선순위 판단 |
| 현장 요구와 현재 실행 수준 간 차이는 어디에서 발생하는가 | 중요도와 실행도의 간극 파악 |
| 중요하게 인식되지만 충분히 제공되지 않는 과정은 무엇인가 | 교육 개입 필요성이 높은 영역 탐색 |
단순히 “필요하다”는 응답만 보는 방식으로는 이 질문에 답하기 어렵다.
예를 들어 어떤 과정은 중요하다고 인식되지만 이미 현장에서 어느 정도 실행되고 있을 수 있고, 반대로 어떤 과정은 중요도는 높은데 실제 실행이 따라오지 못할 수도 있다.
그래서 이번 분석은 중요도와 실행도를 함께 보고, 그 차이인 GAP을 중심으로 우선순위를 해석하는 방식으로 설계했다.
이번 분석의 핵심 지표
이번 프로젝트에서 사용한 핵심 지표는 세 가지다.
| 지표 | 의미 |
| 중요도(Importance) 평균 | 해당 교육과정이 얼마나 중요하게 인식되는가 |
| 실행도(Performance) 평균 | 해당 주제가 현장에서 얼마나 실행되고 있는가 |
| GAP = 중요도 - 실행도 | 중요도 대비 실행 부족 정도 |
특히 이번 분석의 핵심은 GAP이었다.
중요도는 높은데 실행도가 낮다면, 현장에서 필요성은 느끼고 있지만 실제 적용은 충분하지 않다는 뜻이기 때문이다.
데이터 구조 이해하기
설문 원본은 응답 한 행이 하나의 기업 응답이 되고, 각 교육과정마다 중요도와 실행도 컬럼이 붙는 구조라고 가정했다.
예를 들면 다음과 같은 형태다.
- Course_A_Importance
- Course_A_Execution
- Course_B_Importance
- Course_B_Execution
즉, 과정별로 중요도와 실행도가 wide format으로 들어 있는 형태다.
이 구조에서는 먼저 해야 할 일이 각 과정명을 추출하고, 과정별로 중요도 평균·실행도 평균·GAP을 계산할 수 있는 형태로 바꾸는 것이다.
분석 흐름 한눈에 보기
분석 흐름
- 엑셀 파일 불러오기
- 과정 관련 컬럼 추출
- 과정별 중요도 평균 계산
- 과정별 실행도 평균 계산
- GAP 계산
- 요약 테이블 생성
1) 데이터 불러오기
아래 코드는 엑셀 파일을 불러오고, 데이터 구조를 처음 확인하는 단계다.
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams["font.family"] = "Malgun Gothic"
plt.rcParams["axes.unicode_minus"] = False
df = pd.read_excel("../data/mock_survey.xlsx")
print(df.shape)
df.head()코드 포인트
실무에서는 분석보다 먼저 컬럼 구조를 이해하는 일이 중요하다.
어떤 컬럼이 과정 관련 컬럼인지, 네이밍 규칙이 일정한지 먼저 보는 게 이후 자동화 가능성을 좌우한다.
2) 과정 단위로 묶기
과정별 중요도·실행도 평균을 계산하려면 먼저 과정 코드를 추출해야 한다.
# "Course_" 포함 컬럼만 필터링
course_cols = [col for col in df.columns if "Course_" in col]
# 과정 코드만 추출
courses = sorted(set("_".join(col.split("_")[:2]) for col in course_cols))
print(f"총 과정 수: {len(courses)}")
print(courses[:5])이 코드는 컬럼명을 직접 하나씩 쓰지 않아도 된다는 점에서 실용적이다.
과정 수가 늘어나더라도 네이밍 규칙만 유지되면 같은 방식으로 반복 적용할 수 있기 때문이다.
여기서 중요한 점
블로그에서는 단순히 “평균을 계산했다”보다,
반복 가능한 방식으로 구조를 만들었다는 점이 기술 포인트가 된다.
3) 중요도 평균, 실행도 평균, GAP 계산하기
이제 과정별로 평균값을 계산해 요약 테이블을 만든다.
rows = []
for c in courses:
imp_mean = df[f"{c}_Importance"].mean()
exe_mean = df[f"{c}_Execution"].mean()
gap = imp_mean - exe_mean
rows.append([c, imp_mean, exe_mean, gap])
summary_df = pd.DataFrame(
rows,
columns=["과정코드", "중요도 평균", "실행도 평균", "GAP"]
)
summary_df[["중요도 평균", "실행도 평균", "GAP"]] = (
summary_df[["중요도 평균", "실행도 평균", "GAP"]].round(2)
)
summary_df.head()이 단계가 끝나면 설문 응답 단위 데이터가 과정 단위 요약 테이블로 바뀐다.
즉, “응답 데이터”가 “운영 의사결정용 테이블”로 변환되는 셈이다.
예시 출력 테이블
| 과정 코드 | 중요도 평균 | 실행도 평균 | 평균 GAP |
| Course_A | 3.8 | 3.1 | 0.7 |
| Course_B | 3.4 | 3.3 | 0.1 |
| Course_C | 2.9 | 2.1 | 0.8 |
해석 포인트
- 중요도 평균이 높다고 해서 바로 우선순위가 높은 것은 아니다.
- 실행도 평균이 높으면 이미 현장에서 어느 정도 운영되고 있을 가능성이 있다.
- 결국 핵심은 중요도 대비 실행 부족 정도, 즉 GAP이다.
왜 평균 하나만 보면 부족할까
처음에는 중요도 평균만 정렬해서 상위 과정을 고르면 될 것처럼 보일 수 있다.
하지만 실제로는 평균 하나만으로는 부족하다.
예를 들어 중요도와 실행도가 모두 높은 과정은 이미 안정적으로 운영되고 있는 과정일 수 있다. 반면 중요도는 높은데 실행도가 낮은 과정은 “필요하지만 아직 충분히 다뤄지지 않는 영역”일 수 있다. 실제로 프로젝트 정리 문서에서도 중요도와 실행도가 모두 높은 과정보다 GAP이 큰 과정이 상위에 위치했고, 과정 중요도 자체보다 중요 대비 실행 부족 여부가 더 중요한 판단 기준으로 작용했다고 정리되어 있다.
즉, 이번 분석은 단순히 “점수가 높은 과정 찾기”가 아니라,
중요하지만 아직 충분히 실행되지 않는 영역 찾기에 가까웠다.
1편 마무리
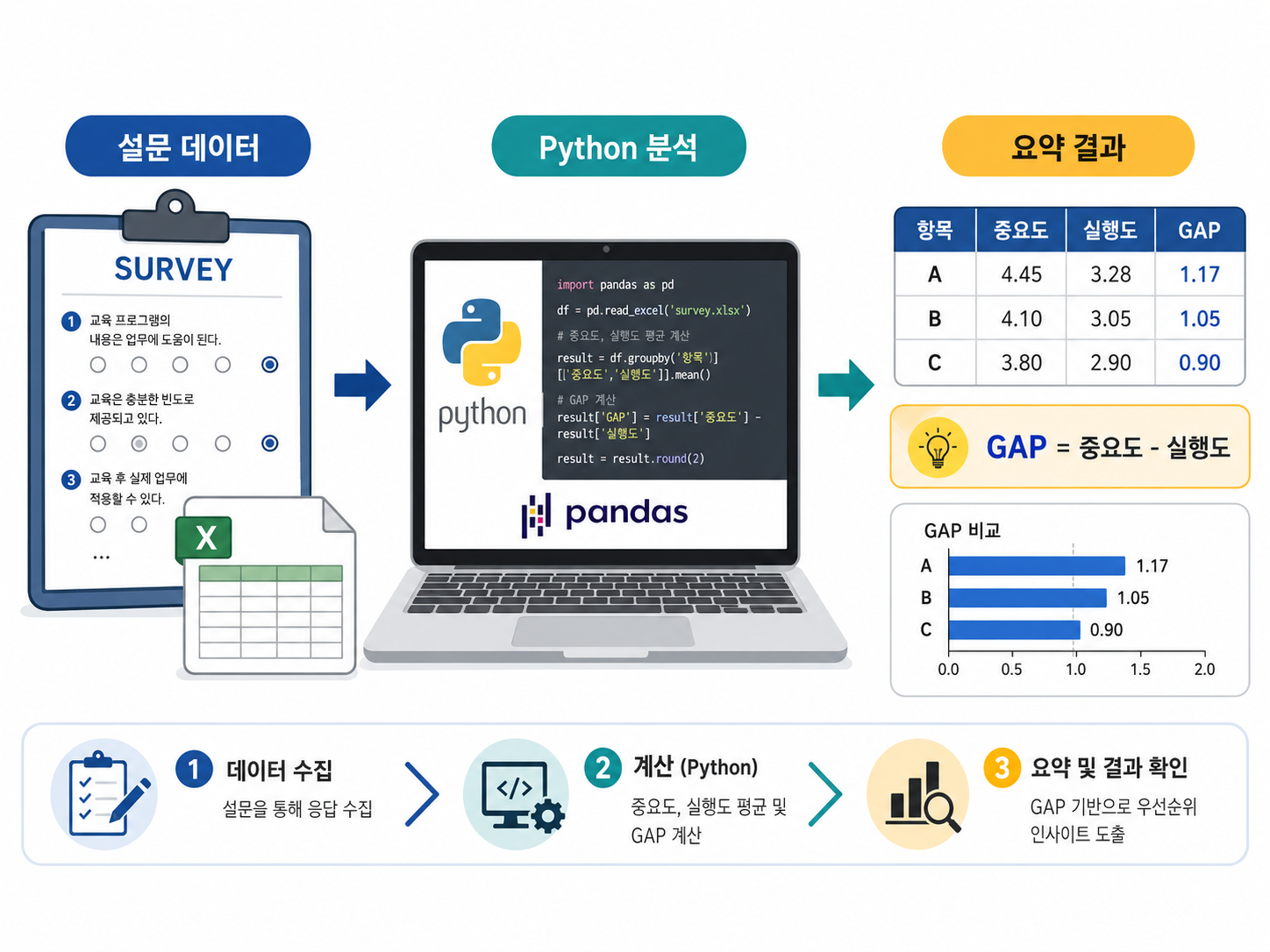
이번 1편에서는 설문 데이터를 Python으로 불러오고, 과정 단위로 묶은 뒤, 중요도 평균·실행도 평균·GAP을 계산해 요약 테이블을 만드는 과정까지 정리했다.
정리하면 핵심은 아래와 같다.
- 설문 원본 데이터를 바로 해석하지 않고, 과정 단위 요약 테이블로 변환했다
- 중요도와 실행도를 분리해 계산했다
- GAP을 통해 중요도 대비 실행 부족 정도를 수치화했다
다음 글에서는 이 summary_df를 바탕으로
운영 전략 분류 함수를 만들고,
GAP 상위 10개 과정과 중요도–실행도 사분면 시각화를 구현한 뒤,
그 결과를 실제 교육 운영 의사결정과 어떻게 연결했는지 정리해보겠다.
https://github.com/devellybutton/Education-Data-Analysis/tree/main/02-training-needs-assessment
Education-Data-Analysis/02-training-needs-assessment at main · devellybutton/Education-Data-Analysis
설문 데이터를 분석해 핵심 지표를 도출하고, 가설 및 통계 검증을 통해 의사결정을 지원한 프로젝트입니다. - devellybutton/Education-Data-Analysis
github.com
https://programming-bellybutton.tistory.com/262
Python으로 교육 수요 설문 분석하기 (2) 시각화와 우선순위 분류
공통 교육과정 우선순위는 어떻게 정리했을까?Python으로 과정 분류하고 시각화해 운영 의사결정까지 연결하기한 줄 요약1편에서 만든 summary_df를 바탕으로, 중요도·실행도·GAP 기준으로 과정을
programming-bellybutton.tistory.com
'실전 기술 활용 > 데이터 분석' 카테고리의 다른 글
| Python으로 교육 수요 설문 분석하기 (2) 시각화와 우선순위 분류 (0) | 2026.06.14 |
|---|---|
| 연말 설문 분석 2편: 주관식 불만 분류부터 KPI 설계까지: 운영 개선 구조 만들기 (0) | 2026.06.14 |
| 연말 설문 분석 1편: Python과 Pandas로 평균 만족도 뒤의 저만족 신호 분석하기 (0) | 2026.06.14 |
| 교육 효과 분석 2편: 분석 결과를 Streamlit 대시보드로 만들기 (0) | 2026.06.03 |
| 교육 효과 분석 1편: 대응표본 t-test로 검증한 교육 전후 변화 (0) | 2026.06.03 |



