
- 분류 전체보기 (254)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- JavaScript
- TiL
- 파이썬프로그래밍기초
- Azure
- 방송대
- 코딩테스트준비
- aws
- node.js
- 코드잇
- 클라우드컴퓨팅
- 코딩테스트
- 꿀단집
- mongoDB
- 엘리스sw트랙
- 개발자취업
- 항해99
- 99클럽
- 방송대컴퓨터과학과
- Python
- CSS
- Git
- 오픈소스기반데이터분석
- 프로그래머스
- 데이터분석
- nestjs
- 유노코딩
- 데이터베이스시스템
- 파이썬
- 중간이들
- HTML
- Today
- Total
배꼽파, 오늘도 배꼽 대신 데이터를 판다
Python으로 교육 수요 설문 분석하기 (2) 시각화와 우선순위 분류 본문
공통 교육과정 우선순위는 어떻게 정리했을까?
Python으로 과정 분류하고 시각화해 운영 의사결정까지 연결하기
한 줄 요약
1편에서 만든 summary_df를 바탕으로, 중요도·실행도·GAP 기준으로 과정을 분류하고 시각화했다.
이 과정을 통해 신규 개설, 보완 필요, 유지, 축소 판단 기준을 만들었다.
https://programming-bellybutton.tistory.com/259
연말 설문 분석 1편: Python과 Pandas로 평균 만족도 뒤의 저만족 신호 분석하기
평균 만족도가 높아도 문제는 숨어 있을 수 있다설문 평균 뒤에 가려진 저만족 신호를 코드로 확인한 과정만족도 설문은 보통 평균부터 본다.문제는 평균이 높아도, 일부 집단의 반복적 불편은
programming-bellybutton.tistory.com
들어가며
지난 글에서는 설문 원본 데이터를 Python으로 불러와 과정별 중요도 평균, 실행도 평균, GAP을 계산하는 과정까지 정리했다.
이번 글에서는 이 요약 테이블을 바탕으로 실제로 어떤 과정을 우선 개설, 보완 필요, 안정 운영, 수요 낮음, 검토 필요로 분류했는지, 그리고 이를 어떤 식으로 시각화했는지 정리한다.
운영 전략 분류 기준 만들기
실무에서는 숫자를 계산하는 것만으로는 부족하다.
결국 "그래서 이 과정을 어떻게 볼 것인가?"라는 질문에 답할 수 있어야 한다.
이번 프로젝트에서는 아래 기준으로 과정을 분류했다.
| 분류 | 판단 기준 | 해석 |
| 우선 개설 | GAP ≥ 0.4 & 중요도 평균 ≥ 3.0 | 중요도는 높지만 실행 수준이 낮음 |
| 보완 필요 | GAP ≥ 0.4 & 중요도 평균 < 3.0 | 실행 부족, 운영 방식 보완 필요 |
| 안정 운영 | GAP < 0.2 & 실행도 평균 ≥ 3.0 | 전반적으로 안정적 운영 가능 |
| 수요 낮음 | GAP < 0.2 & 중요도 평균 < 2.0 | 필요성·활용도 모두 낮음 |
| 검토 필요 | 기타 | 판단 애매, 추가 검토 필요 |
1) 분류 함수 만들기
이제 위 기준을 코드로 옮기면 된다.
def classify(row):
gap = row["GAP"]
imp = row["중요도 평균"]
exe = row["실행도 평균"]
if gap >= 0.4 and imp >= 3.0:
return "우선 개설"
elif gap >= 0.4 and imp < 3.0:
return "보완 필요"
elif gap < 0.2 and exe >= 3.0:
return "안정 운영"
elif gap < 0.2 and imp < 2.0:
return "수요 낮음"
else:
return "검토 필요"
summary_df["해석"] = summary_df.apply(classify, axis=1)
summary_df["해석"].value_counts()코드 포인트
이 함수의 장점은 해석 기준이 코드에 명시된다는 점이다.
이후 과정이 추가되거나 데이터가 업데이트되더라도, 같은 룰로 반복 적용할 수 있다.
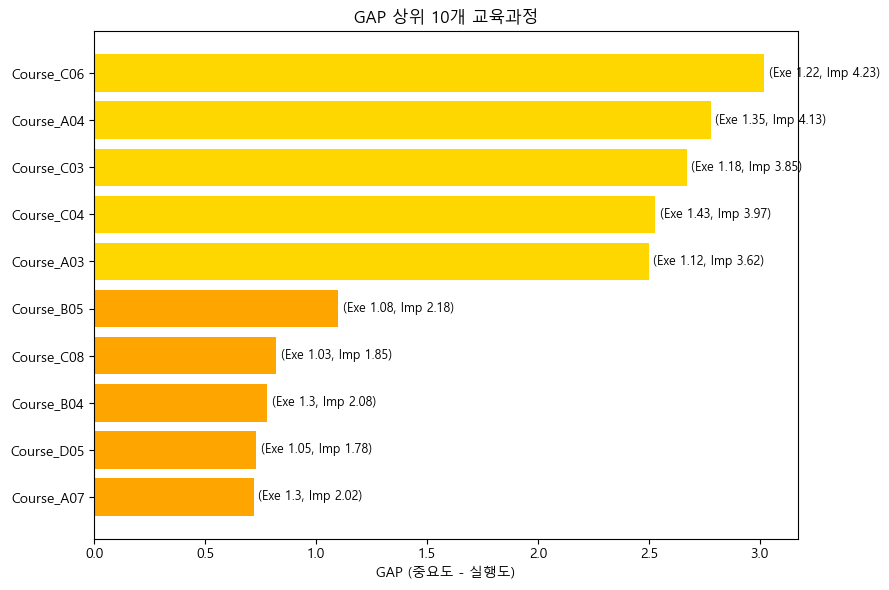
2) GAP 상위 10개 과정 시각화
가장 먼저 만든 시각화는 GAP 상위 10개 과정이다.
이 그래프는 "중요도 대비 실행 부족 정도가 큰 과정"을 빠르게 보여준다.
color_map = {
"우선 개설": "#FFD700",
"보완 필요": "#FFA500",
"안정 운영": "#3498DB",
"검토 필요": "#9B59B6",
"수요 낮음": "#95A5A6"
}
top10 = summary_df.sort_values("GAP", ascending=False).head(10).copy()
top10["색상"] = top10["해석"].map(color_map)
plt.figure(figsize=(9, 6))
plt.barh(
top10["과정코드"],
top10["GAP"],
color=top10["색상"]
)
plt.gca().invert_yaxis()
plt.title("GAP 상위 10개 교육과정")
plt.xlabel("GAP (중요도 - 실행도)")
plt.tight_layout()
plt.show()
3) 중요도–실행도 사분면 시각화
GAP 랭킹만 보면 “당장 뭘 먼저 볼까”는 알 수 있지만, 전체 그림은 보이지 않는다.
그래서 중요도와 실행도를 2차원 좌표로 배치한 사분면 시각화를 함께 만들었다.
중요도 및 실행도는 2차원 좌표 기반으로, GAP은 색상 기반 신호로 표현해 해석의 직관성을 높였다.
import numpy as np
plot_df = summary_df.copy().reset_index(drop=True)
plot_df["번호"] = plot_df.index + 1
x = plot_df["실행도 평균"].to_numpy()
y = plot_df["중요도 평균"].to_numpy()
gap = plot_df["GAP"].to_numpy()
sizes = (np.abs(gap) + 0.2) * 900
norm = plt.Normalize(gap.min(), gap.max())
cmap = plt.cm.RdYlBu_r
colors = cmap(norm(gap))
fig, ax = plt.subplots(figsize=(9, 9))
scatter = ax.scatter(
x, y,
s=sizes,
c=colors,
alpha=0.8,
edgecolor="black"
)
for _, row in plot_df.iterrows():
ax.text(
row["실행도 평균"],
row["중요도 평균"],
str(row["번호"]),
ha="center",
va="center",
fontsize=9
)
ax.set_xlabel("실행도 평균")
ax.set_ylabel("중요도 평균")
ax.set_title("중요도–실행도 사분면")
plt.tight_layout()
plt.show()
시각화에서 읽은 핵심 인사이트
이번 분석에서 중요한 인사이트는 아래와 같았다.
| 관찰 결과 | 해석 |
| 중요도와 실행도가 모두 높은 과정보다 GAP이 큰 과정이 상위에 위치 | 중요도 자체보다 중요 대비 실행 부족 여부가 더 중요 |
| 중요도는 높지만 실행이 부족한 과정 존재 | 교육 개입 여지가 큰 영역 |
| 실행은 높지만 중요도 인식이 낮은 과정 존재 | 운영은 되고 있으나 체감 가치 전달이 약할 가능성 |
| 동일 평균 점수 과정 간 운영 전략 차이 가능 | 평균만으로 판단하면 리스크 발생 |
이 해석은 실제 프로젝트 정리 문서의 인사이트 표와 같은 흐름이다.
특히 과정 중요도 자체보다 중요 대비 실행 부족 여부가 더 중요한 판단 기준으로 작용했다,
중요도는 높지만 실행이 부족한 과정과 실행은 높지만 중요도 인식이 낮은 과정이 함께 존재했다,
동일 평균 점수 과정 간 운영 전략 차이 가능성이 존재했다.
분석 결과가 실제 액션으로 이어진 방식
분석이 의미 있으려면 결국 운영 판단으로 연결되어야 한다.
이번 프로젝트에서는 GAP 기반 우선순위 기준을 세우고, 그 결과를 바탕으로 신규 개설 대상과 운영 축소 대상 과정을 확정했다. 이후 이 결과는 사업계획서에 반영되어 기존 교육과정 통폐합 및 신규 개설 과정 시행으로 이어졌다.
이 지점이 이 프로젝트를 단순한 설문 정리와 다르게 만든다.
즉, 이건 “데이터를 분석했다”보다
“정량 기준이 없던 운영 문제를, 반복 가능한 판단 기준으로 바꿨다”고 설명하는 편이 더 정확하다.
2편 마무리
이번 2편에서는 summary_df를 바탕으로 분류 함수를 만들고, GAP 상위 10개 과정과 중요도–실행도 사분면을 시각화한 뒤, 그 결과를 운영 의사결정과 어떻게 연결했는지 정리했다.
정리하면 핵심은 아래와 같다.
- 중요도·실행도·GAP 기준으로 운영 전략을 분류했다
- Python 코드로 분류 기준을 명시해 재사용 가능하게 만들었다
- 시각화를 통해 우선순위 후보와 전체 구조를 함께 파악했다
- 결과를 실제 신규 개설, 보완, 유지, 축소 판단으로 연결했다
https://github.com/devellybutton/Education-Data-Analysis/tree/main/02-training-needs-assessment
Education-Data-Analysis/02-training-needs-assessment at main · devellybutton/Education-Data-Analysis
설문 데이터를 분석해 핵심 지표를 도출하고, 가설 및 통계 검증을 통해 의사결정을 지원한 프로젝트입니다. - devellybutton/Education-Data-Analysis
github.com
'실전 기술 활용 > 데이터 분석' 카테고리의 다른 글
| Python으로 교육 수요 설문 분석하기 (1) 중요도·실행도·GAP 계산 (0) | 2026.06.14 |
|---|---|
| 연말 설문 분석 2편: 주관식 불만 분류부터 KPI 설계까지: 운영 개선 구조 만들기 (0) | 2026.06.14 |
| 연말 설문 분석 1편: Python과 Pandas로 평균 만족도 뒤의 저만족 신호 분석하기 (0) | 2026.06.14 |
| 교육 효과 분석 2편: 분석 결과를 Streamlit 대시보드로 만들기 (0) | 2026.06.03 |
| 교육 효과 분석 1편: 대응표본 t-test로 검증한 교육 전후 변화 (0) | 2026.06.03 |



